-
Cluster Management, Registration, and DiscoveryDistributedSystem/Manager 2020. 3. 26. 13:42
1. Service Registry and Service Discovery
1.1 Motivation

when a group of computers startup the only device they are aware of is themselves even if they're all connected to the same network the formal logical cluster the different nodes need to find out about each other somehow they need to learn who else is in the cluster and most importantly how to communicate with those other nodes the obvious simple solution can be a static configuration we simply find out all the nodes addresses ahead of time and then we put them all on a single configuration file and distribute the file among all the nodes before we launch the application this way all the nodes can communicate with each other using those addresses the problem, of course, is if one of the nodes becomes unavailable or changes its address after it gets restarted for whatever reason the other nodes would still try to use the old address and will never be able to discover the new address of the node also if we want to expand our cluster we'll have to regenerate this file and distributed the new file to all the nodes.
1.2 Dynamic Configuration
- Some companies still manage their clusters in a similar way, with some degree of automation
- Every time a new node is added, one central configuration is updated
- An automated configuration management tool like Chef or Puppet, can pick up the configuration and distribute it among the nodes in the cluster
1.2.1 Limitation
- More dynamic but still involves a human to update the configuration
2. Service Registry with Zookeeper
we are going to take is using a fully automated service discovery using zookeeper. The idea is as follows we're going to start with a permanent znode called service registry every node that joins the cluster will add an affair sequential node under the service registry node in a similar fashion as in the leader election unlike in the leader election in this case the znodes are not going to be empty instead each node would put its own address inside its znode.

3. Service Discovery

Service discovery now is very easy to implement each node that wants to communicate or even just be aware of any other node in the cluster it's to simply register a watcher on the service registry Z node using the get children method.
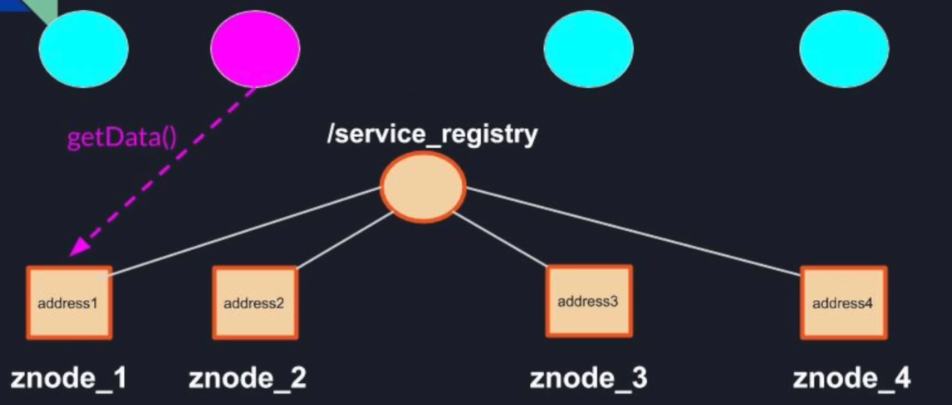

Then when it wants to read or use a particular node address the node will simply need to call the get data method to read the address data stored inside the znode.
If there is any change in the cluster at any point the node is going to get notified immediately with the no children changed event potentially with this implementation

we can implement a fully peer-to-peer architecture.
4. Peer to Peer Architecture

A fully peer-to-peer architecture where each node can communicate freely with any node. in the cluster in that architecture if a node is down or a new node joins the cluster all the nodes will get modified and will act accordingly.
5. Leader / Worker Architecture
The leader workers architecture the workers don't need to know about each other at all and nor does the leader need to register itself in the registry

- Workers will register themselves with the cluster
- Only the leader will register for notifications
- The leader will know about the state of the cluster at all times and distribute the work accordingly
- If a leader dies, the new leader will remove itself from the service registry and continue distributing the work
6. Other technologies
- etcd
- consul
- Netflix Eureka
- Others
7. Reference
https://medium.com/@MPogrebinsky
http://zookeeper.apache.org/doc/current/index.html
https://blog.twitter.com/engineering/en_us/topics/infrastructure/2018/zookeeper-at-twitter.html