-
Hadoop Distributed File System(HDFS)DistributedSystem/HadoopEcyosystem 2019. 9. 8. 21:28
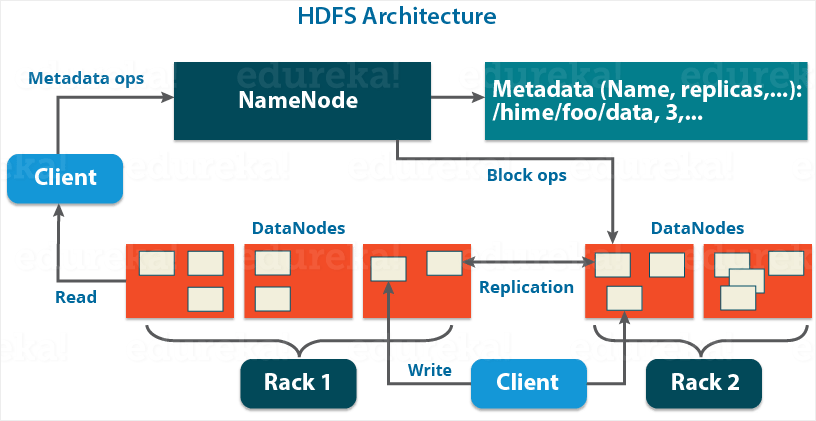
1. Overview
Apache HDFS or Hadoop Distributed File System is a block-structured file system where each file is divided into blocks of a pre-determined size. These blocks are stored across a cluster of one or several machines. HDFS follows a Master/Slave Architecture, where a cluster comprises a single Name node(Master node) and all the other nodes are Data nodes(slave nodes). HDFS can be deployed on a broad spectrum of machines that support Java.

2. Description

2.1 Components of HDFS
Terminology Description Job Tracker - Useful in processing the data
- Job Tracker receives the requests for MapReduce execution from the client
- Job Tracker talks to Name node to know about the location of the data like Job Tracker will request the Name node for the processing data
- Name node in response gives the Metadata to job tracker
Task Tracker - Slave Node for the Job Tracker
- Takes the task from the Job Tracker
- Receive code from the Job Tracker and apply on the file(Known as Mapper)
Name Node - HDFS consists of only one Name Node we call it as Master Node
- Track the files, manage the file system, has the metadata, and whole data in it
- Contains the details of the No. of blocks, Locations at what data node the data is stored, and where the replications are stored and other details
- Single Point Failure
- Direct connection with a client
- Two files Associated with the metadata:
- FsImage: It contains the complete state of the file system namespace since the start of the Name Node
- EditLogs: It contains all the recent modifications made to the file system with respect to the most recent FsImage
Data Node - Stores actual data in it as the blocks
- Also known as the slave node
- Store the actual data into HDFS which is responsible for the client to read and write
- Slave daemons
- Every Data node sends a Heartbeat message to the Name node every 3 seconds
- If Name node does not receive a heartbeat from a data node for 2 minutes, it will take that data node as dead and starts the process of block replications on some other Data node
- Serves up blocks of data over the network using a block protocol specific to HDFS
Secondary NameNode - Constantly reads all the file systems and metadata from the RAM of the NameNode and writes it into the hard disk or file system
- Responsible for combining the EditLogs with FsImage from the NameNode
- Downloads the Editlogs from the NameNode at regular intervals and applies to FsImage
- The new FsImage is copied back to the NameNode, which is used whenever the NameNode is started the next time
Blocks - Smallest continuous location on a hard drive where data is stored
- In any of the File System, Storing the data as a collection of blocks
- Each file as blocks which are scattered throughout the Hadoop cluster
- The default size of each block is 128 MB in Hadoop 2.x
Hadoop Cluster - A single Name node and a cluster of Data nodes
- Redundancy options are available for the Name node due to its criticality(Active/StandBy)
2.2 WorkFlows of Each Component


2.3 Replication Management
- The blocks are also replicated to provide fault tolerance
- The default replication factor is 3 which is again configurable

2.4 Rack Awareness

- NameNode ensure that all the replicas are not stored on the same rack or a single rack
- It follows an in-built Rack Awareness Algorithm to reduce latency as well as provide fault tolerance

2.4.1 Advantages of Rack Awareness
- To improve the network performance
- To prevent loss of data
2.5 HDFS Write Architecture

- At first, the HDFS client will reach out to the NameNode for a Write Request against the two blocks, say, Block A & Block B
- The NameNode will then grant the client the write permission and will provide the IP addresses of the DataNodes where the file blocks will be copied eventually
- The selection of IP addresses of DataNodes is purely randomized based on availability, replication factor and rack awareness
- NameNode will be providing the client with a list of (3) IP addresses of DataNodes.
- Suppose, the NameNode provided the following lists of IP addresses to the client:
- For Block A, list A = {IP of DataNode 1, IP of DataNode 4, IP of DataNode 6}
- For Block B, set B = {IP of DataNode 3, IP of DataNode 7, IP of DataNode 9}
- Each block will be copied in three different DataNodes to maintain the replication factor consistent throughout the cluster.
- Now the whole data copy process will happen in three stages:

2.6 Set up of Pipeline
Before writing the blocks, the client confirms whether the DataNodes, present in each of the list of IPs, are ready to receive the data or not. In doing so, the client creates a pipeline for each of the blocks by connecting the individual DataNodes in the respective list for that block. Let us consider Block A. The list of DataNodes provided by the NameNode is:
For Block A, list A = {IP of DataNode 1, IP of DataNode 4, IP of DataNode 6}.

- The client will choose the first DataNode in the list (DataNode IPs for Block A) which is DataNode 1 and will establish a TCP/IP connection.
- The client will inform DataNode 1 to be ready to receive the block. It will also provide the IPs of next two DataNodes (4 and 6) to the DataNode 1 where the block is supposed to be replicated.
- The DataNode 1 will connect to DataNode 4. The DataNode 1 will inform DataNode 4 to be ready to receive the block and will give it the IP of DataNode 6. Then, DataNode 4 will tell DataNode 6 to be ready for receiving the data.
- Next, the acknowledgment of readiness will follow the reverse sequence, i.e. From the DataNode 6 to 4 and then to 1.
- At last DataNode 1 will inform the client that all the DataNodes are ready and a pipeline will be formed between the client, DataNode 1, 4 and 6.
- Now, pipeline set up is complete and the client will finally begin the data copy or streaming process.
2.7 Data Streaming
As the pipeline has been created, the client will push the data into the pipeline. Now, don’t forget that in HDFS, data is replicated based on the replication factor. So, here Block A will be stored to three DataNodes as the assumed replication factor is 3. Moving ahead, the client will copy the block (A) to DataNode 1 only. The replication is always done by DataNodes sequentially.

- Once the block has been written to DataNode 1 by the client, DataNode 1 will connect to DataNode 4.
- Then, DataNode 1 will push the block in the pipeline and data will be copied to DataNode 4.
- Again, DataNode 4 will connect to DataNode 6 and will copy the last replica of the block.
2.8 A shutdown of Pipeline or Acknowledgement stage
Once the block has been copied into all the three DataNodes, a series of acknowledgments will take place to ensure the client and NameNode that the data has been written successfully. Then, the client will finally close the pipeline to end the TCP session.
As shown in the figure below, the acknowledgment happens in the reverse sequence i.e. from DataNode 6 to 4 and then to 1. Finally, the DataNode 1 will push three acknowledgements (including its own) into the pipeline and send it to the client. The client will inform NameNode that data has been written successfully. The NameNode will update its metadata and the client will shut down the pipeline.

The client will copy Block A and Block B to the first DataNode simultaneously.
Therefore, in our case, two pipelines will be formed for each of the block and all the process discussed above will happen in parallel in these two pipelines.
The client writes the block into the first DataNode and then the DataNodes will be replicating the block sequentially.

As you can see in the above image, there are two pipelines formed for each block (A and B). Following is the flow of operations that is taking place for each block in their respective pipelines:
- For Block A: 1A -> 2A -> 3A -> 4A
- For Block B: 1B -> 2B -> 3B -> 4B -> 5B -> 6B
2.9 HDFS Read Architecture

- The client will reach out to NameNode asking for the block metadata fro the file "example.txt"
- The NameNode will return the list of DataNodes where each block(Block A and B) are stored
- After that client will connect to the DataNodes where the blocks are stored
- The client starts reading data-parallel from the DataNodes
- Once the client gets all the required file blocks, it will combine these blocks to form a file
3. References
https://www.edureka.co/blog/apache-hadoop-hdfs-architecture/
https://searchdatamanagement.techtarget.com/definition/Hadoop-Distributed-File-System-HDFS
https://www.geeksforgeeks.org/introduction-to-hadoop-distributed-file-systemhdfs/
'DistributedSystem > HadoopEcyosystem' 카테고리의 다른 글
Hadoop (0) 2020.03.09 Big Data (0) 2019.09.25 MapReduce (0) 2019.09.25 Difference between Hadoop and Spark (0) 2019.09.25 Hadoop Yet Another Resource Negotiator(Yarn) (0) 2019.09.14