-
MapReduceDistributedSystem/HadoopEcyosystem 2019. 9. 25. 05:08
1. Overview
a processing technique and a program model for distributed computing based on java. The MapReduce algorithm contains two important tasks, namely Map and Reduce. The major advantage of MapReduce is that it is easy to scale data processing over multiple computing nodes. Under the MapReduce model, the data processing primitives are called mappers and reducers. Decomposing a data processing application into mappers and reducers is sometimes nontrivial. But, once we write an application in the MapReduce form, scaling the application to run over hundreds, thousands, or even tens of thousands of machines in a cluster is merely a configuration change. This simple scalability is what has attracted many programmers to use the MapReduce model.
1.1 Map
- Takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs)
1.2 Reduce
- Reduce task, which takes the output from a map as an input and combines those data tuples into a smaller set of tuples.
- Reduce task is always performed after the map job
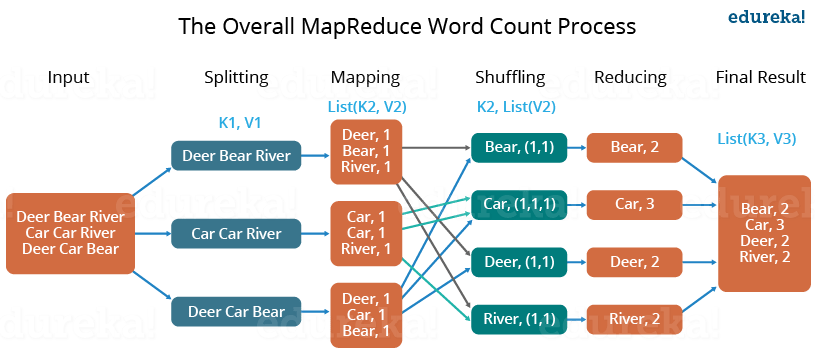
2. Description
2.1 Features
Features Description Parallel Processing - Dividing the job among multiple nodes and each node works with a part of the job simultaneously.
- Based on Divide and Conquer paradigm which helps us to process the data using different machines
- The data is processed by multiple machines instead of a single machine in parallel
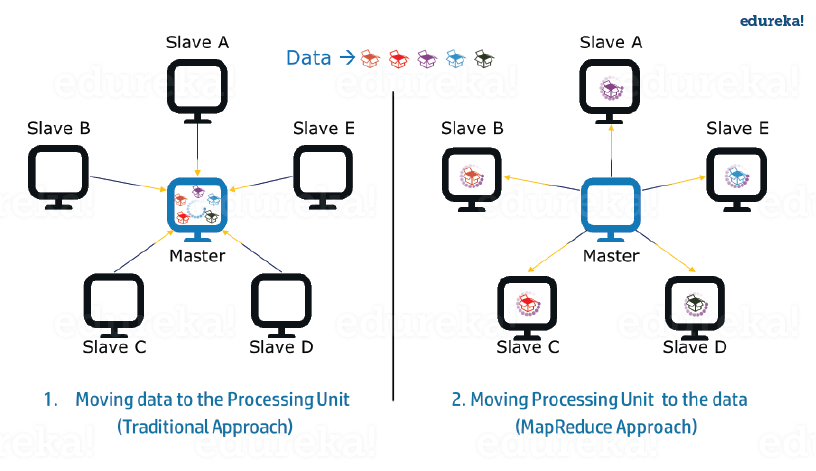
Data Locality - Moving processing unit to the data in the MapReduce Framework
- Every node gets a part of the data to process and therefore, there is no chance of a node getting overburdened.
- The processing time is reduced as all the nodes are working with their part of the data in parallel.
- It is very cost-effective to move the processing unit to the data.
- Resolving traditional following issues
- Resolving Moving huge data to processing is costly and deteriorates the network performance.
- Processing takes time as the data is processed by a single unit which becomes the bottleneck.
- The master node can get over-burdened and may fail.
2.2 Components
Component Description Payload Applications implement the Map and Reduce functions, and form the core of the job Mapper Mapper maps the input/value pairs to a set of intermediate key/value pair NamedNode A node that manages the Hadoop Distributed File System(HDFS) DataNode The node where data is presented in advance before any processing from clients MasterNode The node where JobTracker runs and which accepts job requests from clients SlaveNode The node where the Map and Reduce program runs JobTracker Schedules jobs and tracks the assign jobs to Task tracker Task Tracker Tracks the task and reports status to JobTracker Job A program is an execution of a Mapper and Reducer across a dataset Task Execution of a Mapper or a Reducer on a slice of data Task Attempt A particular instance of an attempt to execute a task on a SlaveNode 3. Example
3.1 Mapper
- Extends the Mapper class in MapReduce Framework
- Define the data types of input and output key/value pair after the class declaration using angle brackets.
- Both the input and output of the Mapper is a key/value pair.

3.1.1 Input:
- The key is nothing but the offset of each line in the text file: LongWritable
- The value is each individual line (as shown in the figure at the right): Text
3.1.2 Output:
- The key is the tokenized words: Text
- We have the hardcoded value in our case which is 1: IntWritable
- Example – Dear 1, Bear 1, etc.
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> { public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { value.set(tokenizer.nextToken()); context.write(value, new IntWritable(1)); }3.2 Reducer
- Created a Reduce Class which extends class Reducer like that of Mapper.
- Define the data types of input and output key/value pair after the class declaration using angle brackets as done for Mapper.
- Both the input and the output of the Reducer is a key-value pair.
- Have aggregated the values present in each of the list corresponding to each key and produced the final answer.
- In general, a single reducer is created for each of the unique words, but, you can specify the number of reducer in mapred-site.xml.
3.2.1 Input:
- The key nothing but those unique words which have been generated after the sorting and shuffling phase: Text
- The value is a list of integers corresponding to each key: IntWritable
- Example – Bear, [1, 1], etc.
3.2.2 Output:
- The key is all the unique words present in the input text file: Text
- The value is the number of occurrences of each of the unique words: IntWritable
- Example – Bear, 2; Car, 3, etc.
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> { public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException { int sum=0; for(IntWritable x: values) { sum+=x.get(); } context.write(key, new IntWritable(sum)); } }- Driver
Configuration conf= new Configuration(); Job job = new Job(conf,"My Word Count Program"); job.setJarByClass(WordCount.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path outputPath = new Path(args[1]); //Configuring the input/output path from the filesystem into the job FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));- In the driver class, set the configuration of our MapReduce job to run in Hadoop.
- Specify the name of the job , the data type of input/output of the mapper and reducer.
- Specify the names of the mapper and reducer classes.
- The path of the input and output folder is also specified.
- The method setInputFormatClass () is used for specifying how a Mapper will read the input data or what will be the unit of work. Here, we have chosen TextInputFormat so that a single line is read by the mapper at a time from the input text file.
- The main () method is the entry point for the driver. In this method, we instantiate a new Configuration object for the job.
4. References
'DistributedSystem > HadoopEcyosystem' 카테고리의 다른 글
Hadoop (0) 2020.03.09 Big Data (0) 2019.09.25 Difference between Hadoop and Spark (0) 2019.09.25 Hadoop Yet Another Resource Negotiator(Yarn) (0) 2019.09.14 Hadoop Distributed File System(HDFS) (0) 2019.09.08