-
Apache SparkDistributedSystem/Spark 2019. 9. 20. 00:55
1. Overview
An open-source distributed general-purpose cluster computing framework with mostly in-memory data processing engine that can do ETL, analytics, machine learning, and graph processing on large volumes of data at rest(batch processing) or in motion(streaming processing) with rich concise high-level APIs for the programming languages: Scala, Python, Java, R, and SQL
2. Description
2.1 Apache Spark Core
Spark Core consists of a general execution engine for spark platform that all required by other functionality which is built upon as per the requirement approach. It provides in-built memory computing and referencing datasets stored in external storage systems.
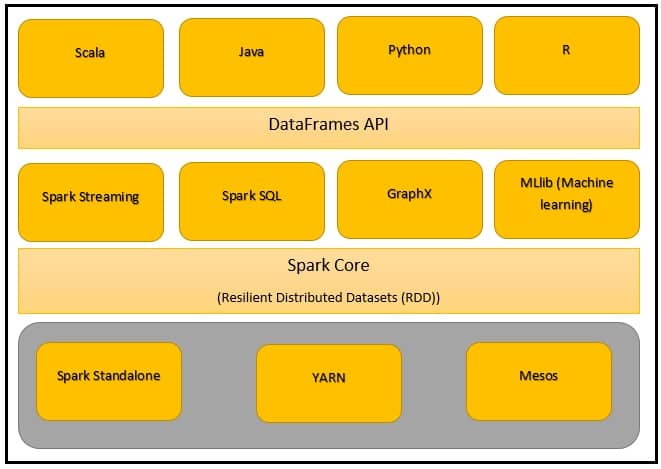
2.2 Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new set of data abstraction called Schema RDD, which provides support for both the structured and semi-structured data. It enables users to run SQL/HQL queries on the top of Spark. It also provides an engine for Hive to run unmodified queries up to 100 times faster on existing deployments
Below is an example of a Hive compatible query: // sc is an existing SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) sqlContext.sql(“CREATE TABLE IF NOT EXISTS src (key INT, value STRING)”) sqlContext.sql(“LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt’ INTO TABLE src”) // Queries are expressed in HiveQL sqlContext.sql(“FROM src SELECT key, value”).collect().foreach(println)
2.3 Spark Streaming
This spark component allows Spark to process real-time streaming data. It provides an API to manipulate data streams that match with RDD API. It allows the programmers to understand the project and switch through the applications that manipulate the data and giving outcomes in real-time. Similar to Spark Core, Spark Streaming strives to make the system fault-tolerant and scalable
2.3.1 RDD API Examples
In this example, we will use a few transformations that are implemented to build a dataset of (String, Int) pairs called counts and then save it to a file.
text_file = sc.textFile("hdfs://...") counts = text_file.flatMap(lambda line: line.split(” “)) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile(“hdfs://…”)2.4 MLlib(Machine Learning Library)
Apache Spark is equipped with a rich library known as MLlib. This library contains a wide array of machine learning algorithms, classification, clustering and collaboration filters, etc. It also includes a few lower-level primitives. All these functionalities help Spark scale out across a cluster.
2.4.1 Prediction with Logistic Regression
In this example, we take dataset values in terms of labels and feature vectors. We learn to predict the labels from feature vectors using the method of Logistic algorithm using the python language:
# Every record of this DataFrame contains the label and # features represented by a vector. df = sqlContext.createDataFrame(data, [“label”, “features”]) # Set parameters for the algorithm. # Here, we limit the number of iterations to 10. lr = LogisticRegression(maxIter=10) # Fit the model to the data. model = lr.fit(df) # Given a dataset, predict each point’s label, and show the results. model.transform(df).show()2.5 GraphX
Spark also comes with a library to manipulate the graphs and performing computations, called GraphX. Just like Spark Streaming and Spark SQL, GraphX also extends Spark RDD API which creates a directed graph. It also contains numerous operators in order to manipulate the graphs along with graph algorithms.
Consider the following example to model users and products as a bipartite graph we might follow:
class VertexProperty()case class UserProperty(val name: String) extends VertexProperty
case class ProductProperty(val name: String, val price: Double) extends VertexProperty
// The graph might then have the type:
var graph: Graph[VertexProperty, String] = null
3. Programming Model
Spark programming is based on parallelizable operators Parallelizable operators are higher-order functions that execute user-defined functions in parallel A data flow is composed of any number of data sources, operators, and data sinks by connecting their inputs and outputs Job description is based on directed acyclic graphs(DAG) Spark allows programmers to develop complex, multi-step data pipelines using directed acyclic graph(DAG) pattern Since spark is based on DAG, it can follow a chain from child to parent to fetch any value like tree traversal DAG supports fault-tolerance 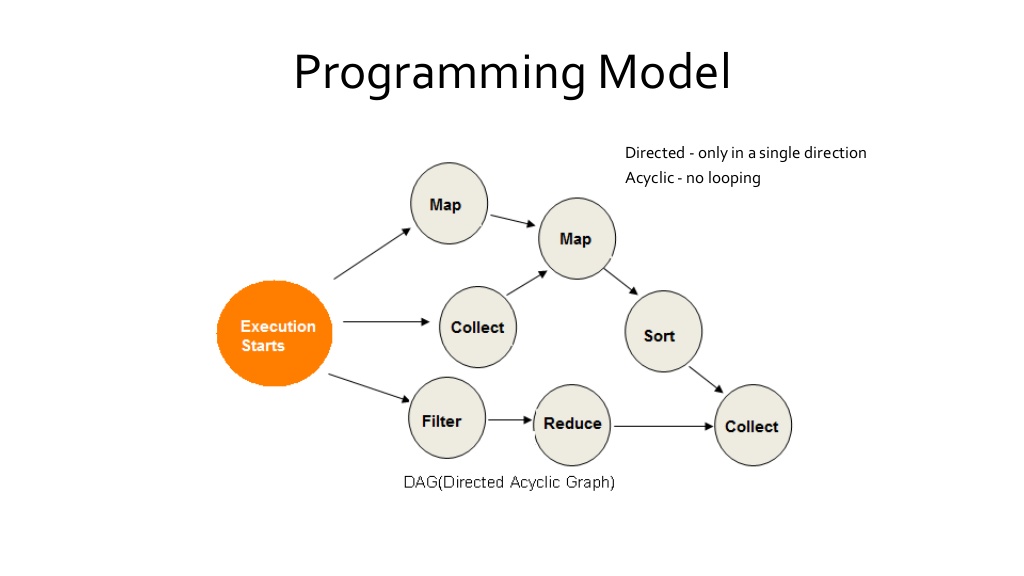
4. Job Architecture
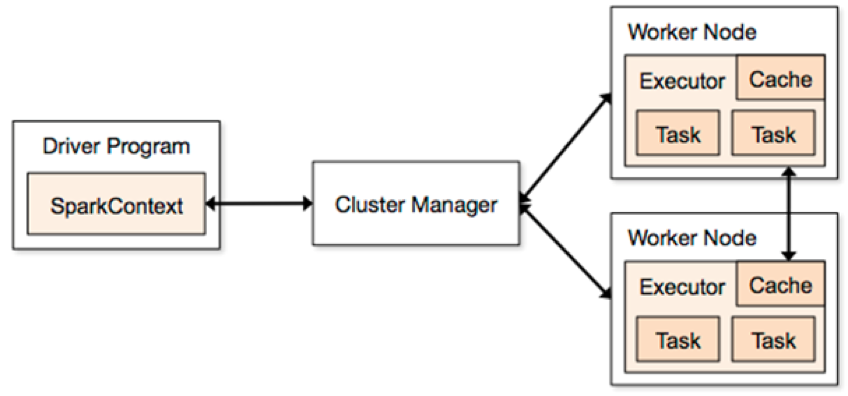
4.1 Job Driver
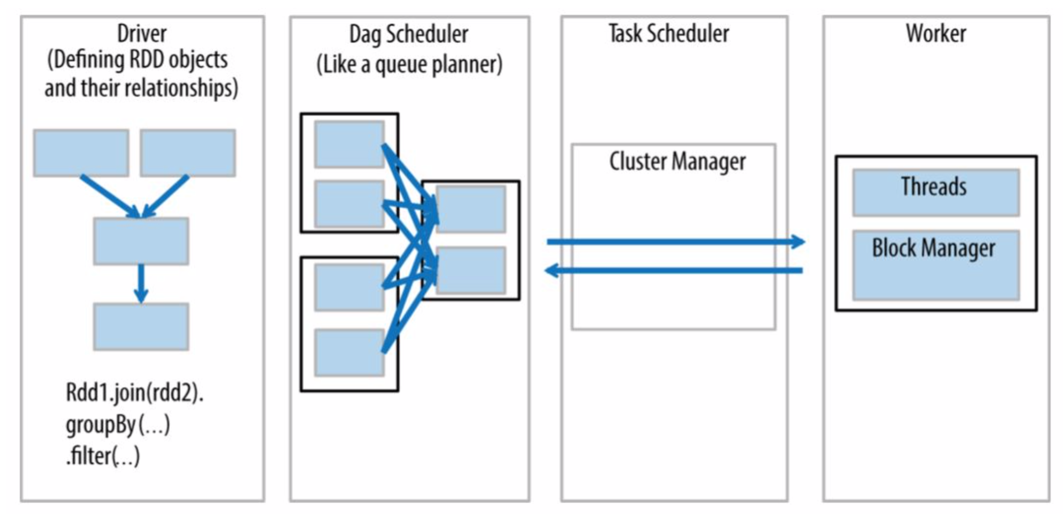
- The Driver is the code that includes the “main” function and defines the RDDs
- Parallel operations on the RDDs are sent to the DAG scheduler, which will optimize the code and arrive at an efficient DAG that represents the data processing steps in the application.
- Cluster Managers
- The resulting DAG is sent to the ClusterManager. The cluster manager has information about the workers, assigned threads, and location of data blocks and is responsible for assigning specific processing tasks to workers.
- The cluster manager is also the service that handles DAG play-back in the case of worker failure
- Spark is designed to efficiently scale up from one to many thousands of compute nodes.
- It can run over a variety of cluster managers including Hadoop, YARN, Apache Mesos, etc.
- Spark has a simple cluster manager included in Spark itself called the Standalone Scheduler
4.2 Executor/Workers
- run tasks scheduled by a driver
- executes its specific task without knowledge of the entire DAG
- store computation results in memory, on disk or off-heap
- interact with storage systems
- send its results back to the Driver application
4.3 Fault Tolerance
RDDs store their lineage — the set of transformations that were used to create the current state, starting from the first input format that was used to create the RDD.
If the data is lost, Spark will replay the lineage to rebuild the lost RDDs so the job can continue.
Let’s see how this works:
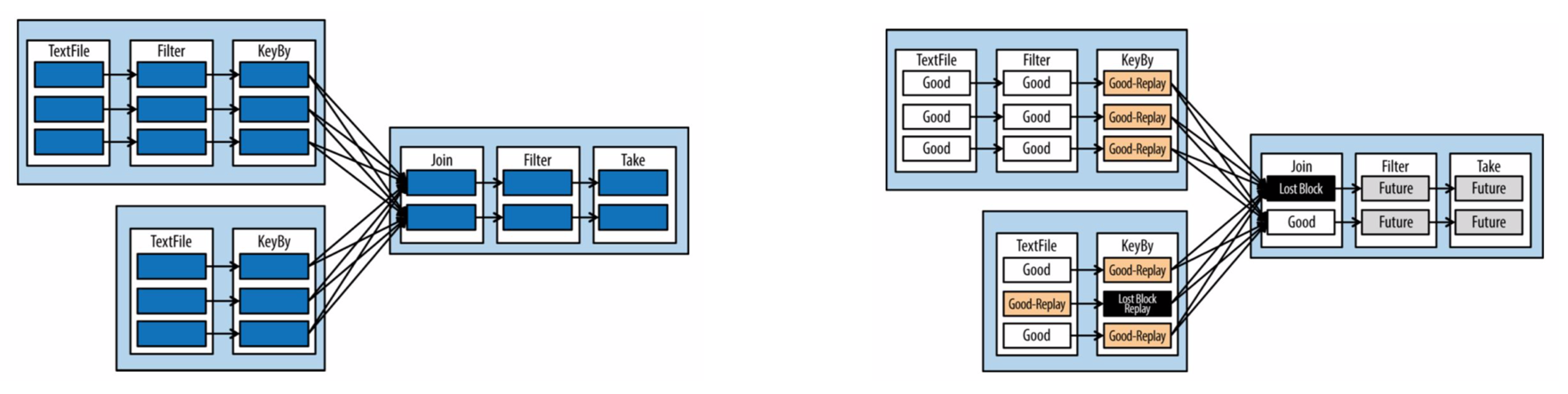
The left image is a common image used to illustrate a DAG in spark. The inner boxes are RDD partitions; the next layer is an RDD and single chained operation.
If we lose the partition denoted by the black box. Spark would replay the “Good Replay” boxes and the “Lost Block” boxes to get the data needed to execute the final step
4.4 Execution Workflow
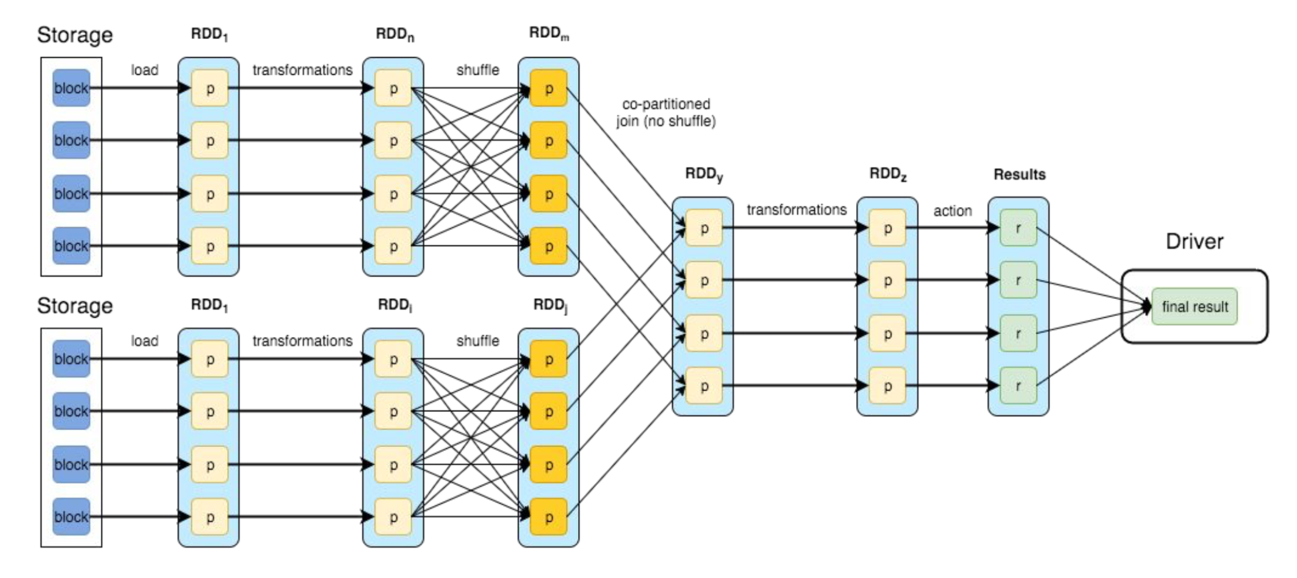
- Client/user defines the RDD transformations and actions for the input data
- DAGScheduler will form the most optimal Direct Acyclic Graph which is then split into stages of tasks.
- Stages combine tasks which don’t require shuffling/repartitioning if the data
- Tasks are then run on workers and results are returned to the client
Let's take a look at how stages are determined by looking at an example of a more complex job’s DAG
4.5 Dependency Types
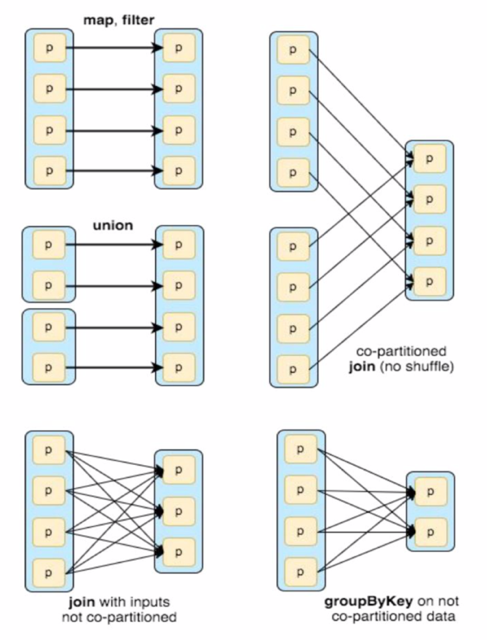
4.5.1 Narrow (pipeline able)
- Each partition of the parent RDD is used by at most one partition of the child RDD
- Allow for pipelined execution on one cluster node
- Failure recovery is more efficient as only lost parent partitions need to be recomputed
4.5.2 Wide (shuffle)
- Multiple child partitions may depend on one parent partition
- Require data from all parent partitions to be available and to be shuffled across the nodes
- If some partition is lost from all the ancestors a complete re-computation is needed
4.6 Stages and Tasks
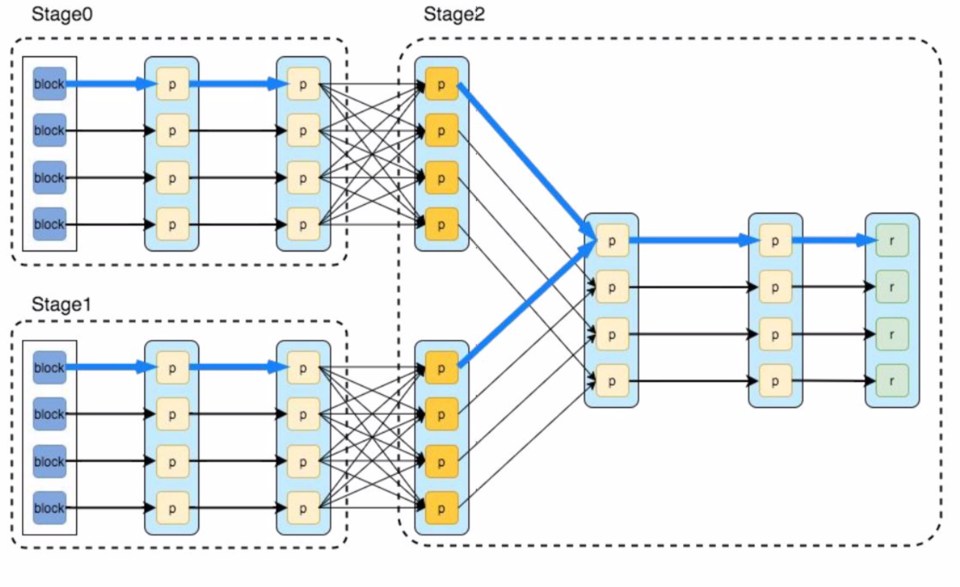
4.6.1 Stages of breakdown strategy
- Check backward from final RDD
- Add each “narrow” dependency to the current stage
- Create a new stage when there’s a shuffle dependency
4.6.2 Tasks
- ShuffleMapTask partitions its input for shuffle
- ResultTask sends its output to the driver
4.7 Stages Summary
Summary or the staging strategies:
- RDD operations with “narrow” dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage
- Operations with “wide” /shuffle dependencies require multiple stages (one to write a set of map output files, and another to read those files after a barrier).
- In the end, every stage will have only shuffle dependencies on other stages and may compute multiple operations inside it
4.8 Shared Variables
- Spark includes two types of variables that allow sharing information between the execution nodes: broadcast variables and accumulator variables.
- Broadcast variables are sent to all the remote execution nodes, where they can be used for data processing.
- This is similar to the role that Configuration objects play in MapReduce.
- Accumulators are also sent to the remote execution nodes, but unlike broadcast variables, they can be modified by
the executors, with the limitation that you only add to the accumulator variables. - Accumulators are somewhat similar to MapReduce counters.
4.9 SparkContext
- SparkContext is an object that represents the connection to a Spark cluster.
- It is used to create RDDs, broadcast data, and initialize accumulators.
4.10 Transformations
- Transformations are functions that take one RDD and return another
- RDDs are immutable, so transformations will never modify their input, only return the modified RDD.
- Transformations in Spark are always lazy, so they don’t compute their results. Instead, calling a transformation function only creates a new RDD with this specific transformation as part of its lineage.
- The complete set of transformations is only executed when an action is called
4.11 Most Common Transformations
map() — Applies a function on every element of an RDD to produce a new RDD. This is similar to the way the MapReduce map() method is applied to every element in the input data. For example lines.map(s=>s.length) takes an RDD of Strings (“lines”) and returns an RDD with the length of the strings.
filter() — Takes a Boolean function as a parameter, executes this function on every element of the RDD, and returns a new RDD containing only the elements for which the function returned true. For example, lines.filter(s=>(s.length>50)) returns an RDD containing only the lines with more than 50 characters.
keyBy() — Takes every element in an RDD and turns it into a key-value pair in a new RDD. For example, lines.keyBy(s=>s.length) return, an RDD of key-value pairs with the length of the line as the key, and the line as the value.
join() — Joins two key-value RDDs by their keys. For example, let’s assume we have two RDDs: lines and more_lines. Each entry in both RDDs contains the line length as the key and the line as the value. lines.join(more_lines) will return for each line length a pair of Strings, one from the lines RDD and one from the more_lines RDD. Each resulting element looks like <length,<line,more_line>>.
groupByKey() — Performs a group-by operation on an RDD by the keys. For example lines.group ByKey() will return an RDD where each element has a length as the key and a collection of lines with that length as the value
sort() — Performs a sort on an RDD and returns a sorted RDD.
Note that transformations include functions that are similar to those that MapReduce would perform in the map phase, but also some functions, such as groupByKey(), that belong to the reduce phase.
4.12 Actions
- Actions are methods that take an RDD, perform a computation, and return the result to the driver application.
- Actions trigger the computation of transformations.
- The result of the computation can be a collection, values printed to the screen, values saved to file, or similar.
- However, an action will never return an RDD.
4.13 Example Job
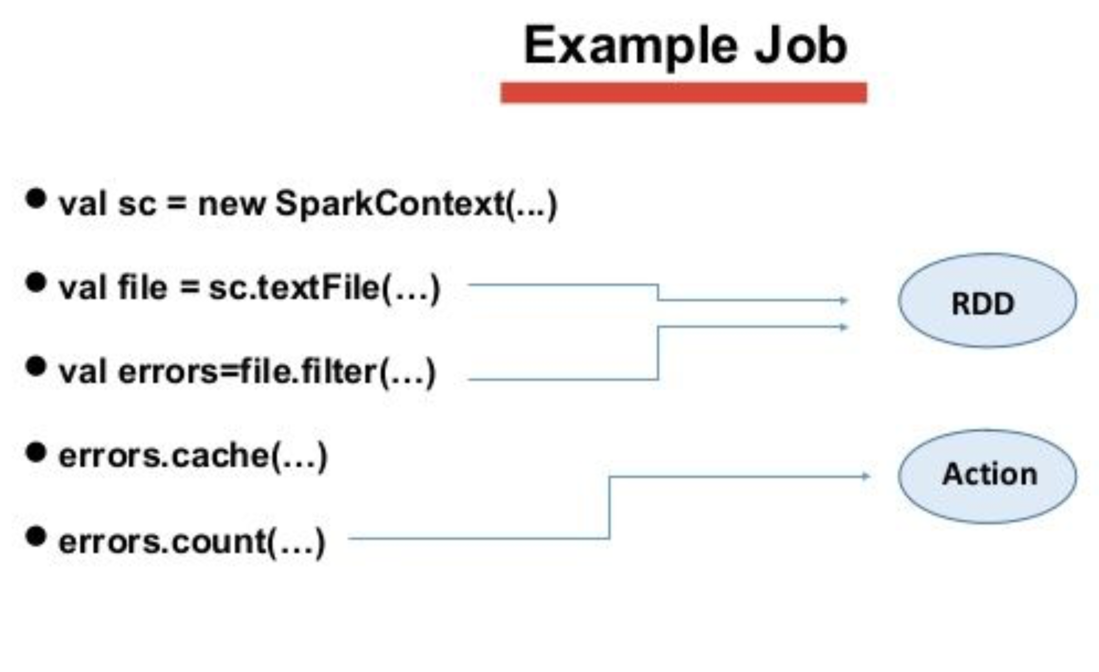
- To start, we initialize a new SparkContext to run commands on our Spark cluster.
- We read in a local log file that we want to process that creates an RDD.
- We put the filter transformation and create a new RDD called errors. We want to check for logs that have error messages.
- The cache commands stores our RDD in memory.
- The count action is executed. It runs the lazy transformation from before and prints out a value that represents the number of error messages in our log file.
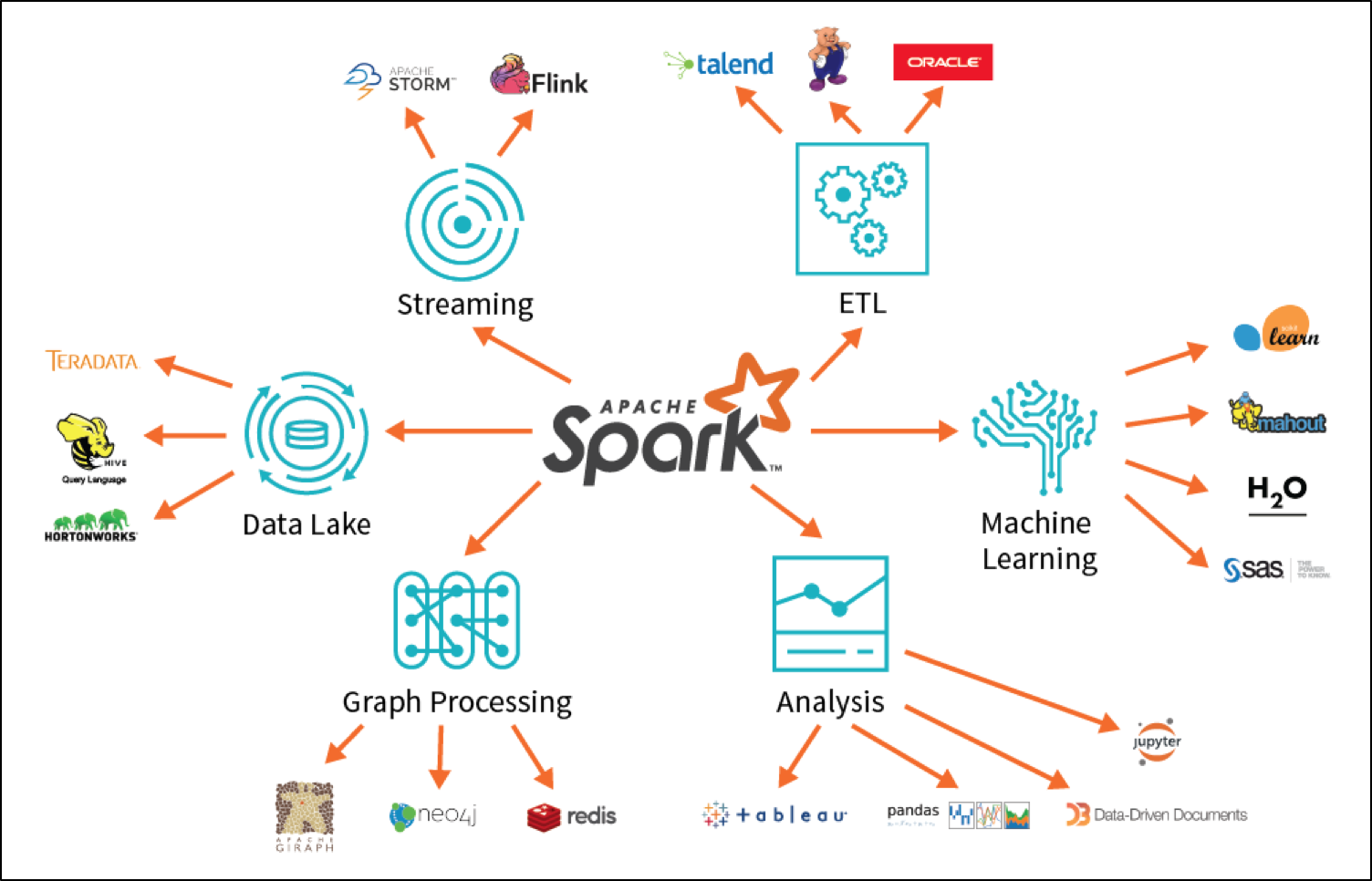
5. Ecosystem of Spark
6. References
https://blog.k2datascience.com/batch-processing-apache-spark-a67016008167
https://data-flair.training/blogs/what-is-spark/
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-overview.html
http://bigdatascholars.blogspot.com/2018/07/spark-interview-questions.html
https://intellipaat.com/blog/tutorial/spark-tutorial/apache-spark-components/
https://www.slideshare.net/GirishKhanzode/apache-spark-core
https://spark.apache.org/docs/1.1.1/graphx-programming-guide.html
https://databricks.com/blog/2016/06/22/apache-spark-key-terms-explained.html
'DistributedSystem > Spark' 카테고리의 다른 글
MapReduce Vs Spark RDD (0) 2019.09.25 RDD Lineage and Logical Execution Plan (0) 2019.09.25 Difference between RDD and DSM (0) 2019.09.25 Resilient Distributed Dataset(RDD) (0) 2019.09.08