-
Term frequency–inverse document frequency(TF-IDF)MLAI/Preprocessing 2019. 9. 25. 01:34
1. Overview
A document-term or term-document matrix consists of the frequency of terms that exist in a collection of documents. In the document-term matrix, rows represent documents in the collection and columns represent terms whereas the term-document matrix is the transpose of it.
1.1 Motivation
we have a large number of documents:
- Books
- Academic Articles
- Legal Documents
- Websites
- etc
A user then provides us with a search query in real-time to get the most relevant documents or links to their search based on that search query we want to identify which documents are more relevant and which are less relevant and present all those results to the user
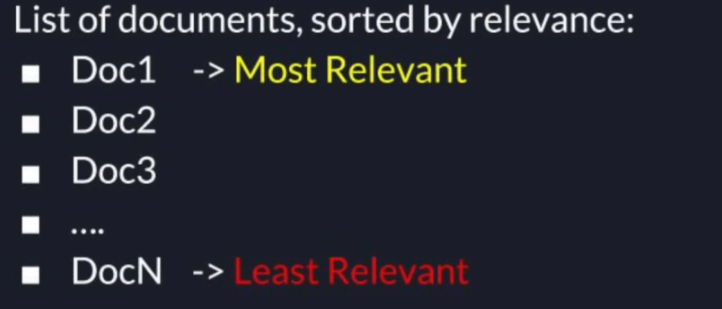
So given those documents in a search query how are we going to decide which documents are more relevant?
2. Search Algorithm
2.1 Simple Count
The simplest approach we can take is a simple word count of our search terms. We can simply count how many times each search term from the query appears in each document. Then documents, where the search terms appear many times will rank high in relevance and documents where the search terms don't appear as much will rank lower
2.1.1 Problem
The algorithm favors larger documents
Search Term: "car"
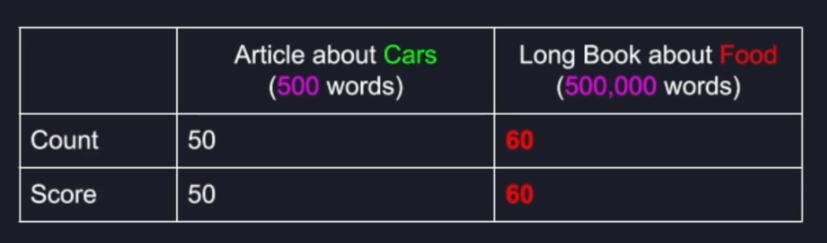
2.2 Term Frequency
Term Frequency = (term count) / (total number of words in document)
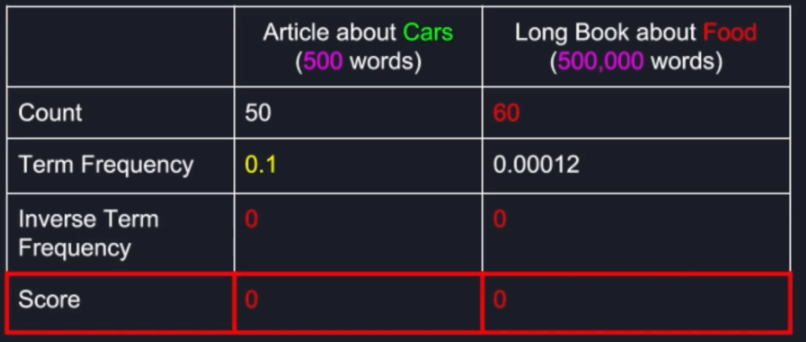
This gives us the relative term frequency in each document instead of just a row count. if we apply that approach, in this case, we clearly see that the word car appears every 10 words in the short article about cars whereas in the irrelevant long document the word car constitutes only about 0.01% which means it appears only about every eight thousand words.
2.2.1 Problem
Search Query: "The fast Car"
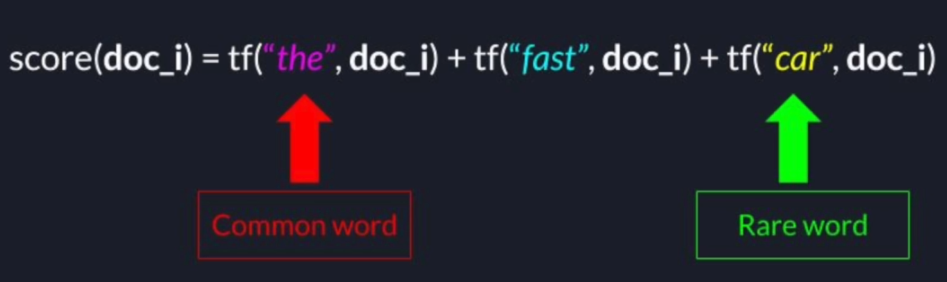

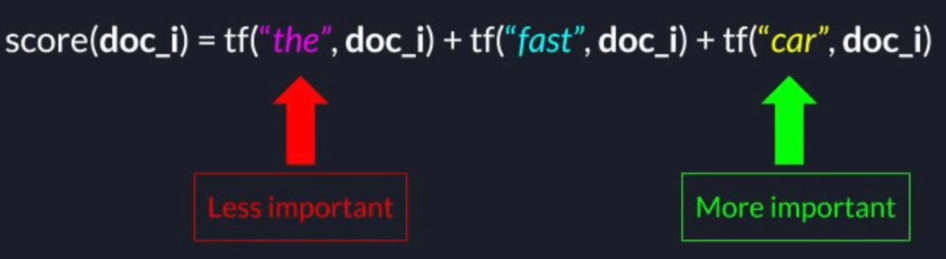
2.3 Term Frequency - Inverse Document Frequency (TF-IDF)
- TF-IDF measures how much information each term in the search query provides us
- Common terms that appear in many documents do not provide us any value and get a lower weight
- Terms that are rarer across all documents, get higher weight.
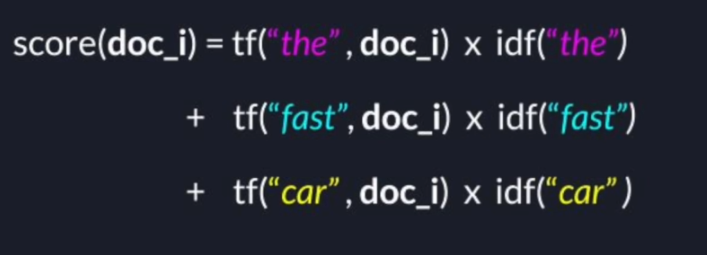
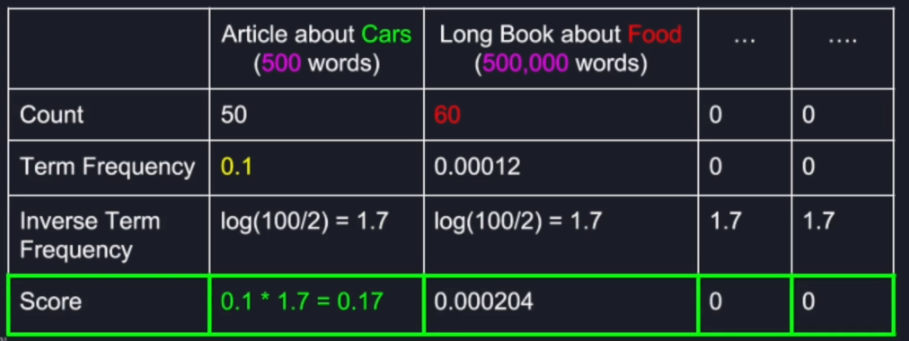
2.3.1 Inverse Document Frequency
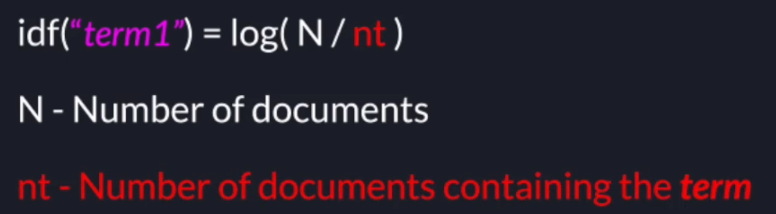
idf(term) = log(N/nt)
where N is the number of documents, nt is the number of documents containing the term at least once.
2.4 Example



2.5 Notes
TF-IDF is a statistical algorithm and requires a large enough set of documents to give good results.
- The algorithm works well with a high number of documents and is highly parallelizable
- Perfect fit for building a distributed system
Search Term: "car"
3. Parallel TF-IDF
3.1 Problems Dimensions
We have to decide on which dimension we want to parallelize the algorithm. Since we have the search terms on one hand and the documents, on the other hand, we can split the work only on one of those dimensions.
for(Document doc: documents) { for(Term term: query) { doc.score += tf(term, doc) * idf(term) } } sort(documents, by score) // list of relevant documents- D: Number of documents
- T: Number of Searches Terms
We can either partition the problem by terms giving each node a subset of the search terms and all the documents are going to be shared or we can partition the data by documents giving each node a subset of the documents in our repository and all the search terms are going to be shared by all nodes.
3.1.1 Deciding how to parallelize the workload
- The decision on how to parallelize the algorithm is critical to make the algorithm scalable
- We need to choose the dimension on which the input to our system is expected to grow the most
- If/When the data does grow, then we can simply add more machines to the cluster, and the system will easily scale
3.1.2 Choosing the Dimension for Data partitioning
- Do we expect the number of terms in the query to grow significantly? No
- Do we expect the number of documents to grow over time? Yes
- Then we choose to parallelize the TF-IDF algorithm by the documents
3.1.3 Term Frequency

The term frequency and the inverse document frequency we can easily calculate the term frequency in parallel by different nodes as each term frequency it depends on the term and the words in one particular document and that's great news for us since scanning through all the words in each document is the most intensive operation.
3.1.4 Inverse Document Frequency
Unfortunately, the IDF cannot be calculated in parallel by different nodes and that's because to calculate the inverse document frequency for each given node we need the information from all the documents in the repository
3.2 Parallel Processing
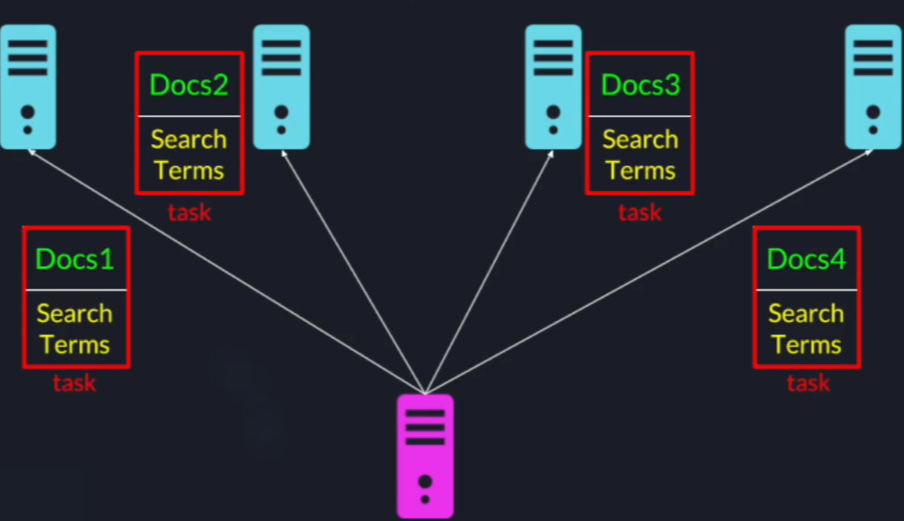
The leader will take the documents and split them evenly among the notes then the leader will send a task to each node it contains all the terms and the subset of documents allocated to that particular node.
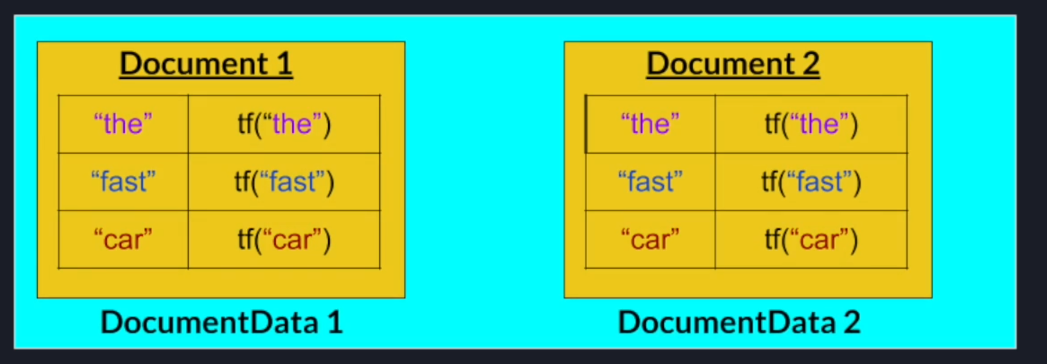
Each node that will create a map for each document allocated to it each of those maps will map from a search term to its term frequency in that particular document that map is exactly the document data class we defined in our original implementation
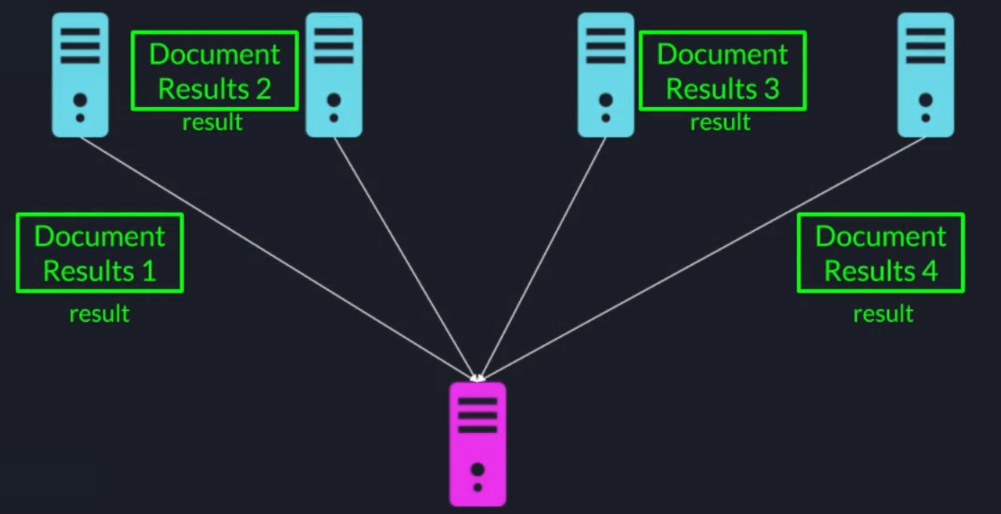
Then each node will aggregate all the document data objects for all its allocated documents and send the results back to the leader at this point the leader will have all the term frequencies for all the terms in all the documents.
3.3 Aggregation
- Calculate all the IDF for all the terms easy to derive from the term frequencies
- Score the documents
- Sort the document by relevance
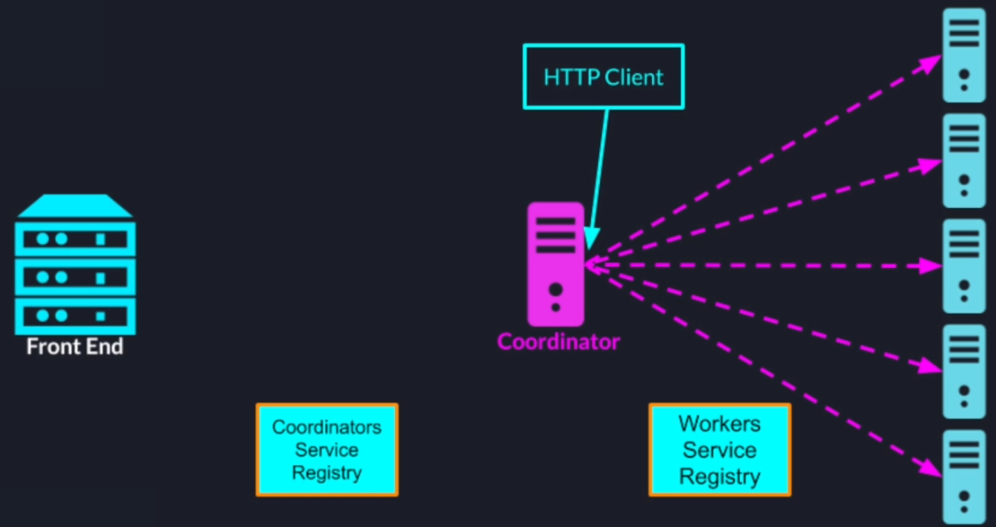
4. System Architecture and Request Handling
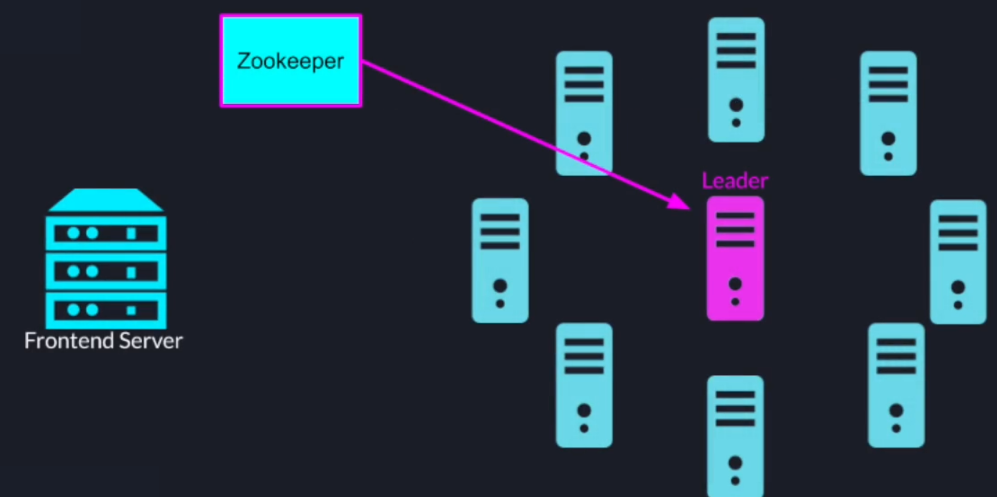
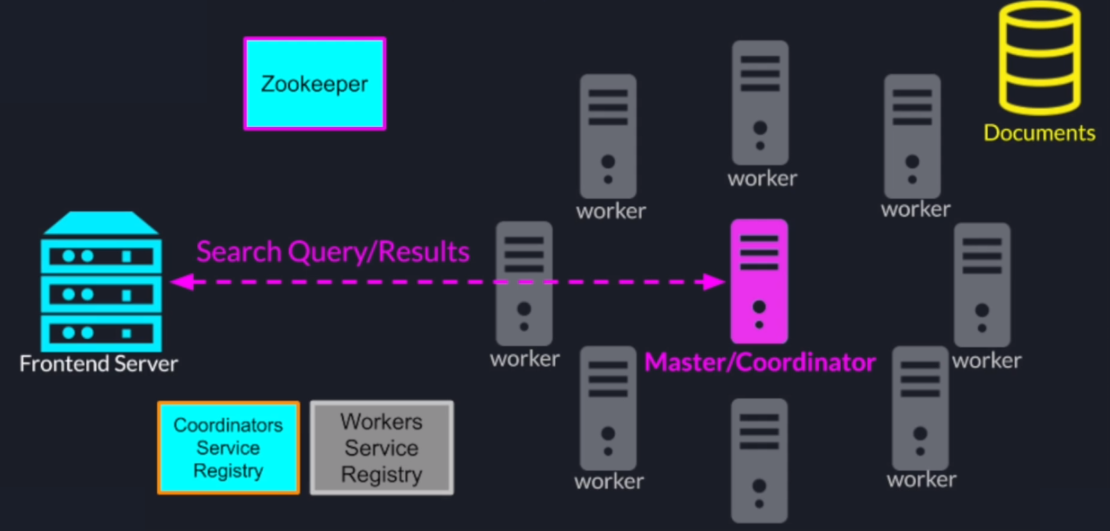
First of all, we have our cluster of search nodes in the front-end server then using zookeeper we elect a leader to act as a coordinator
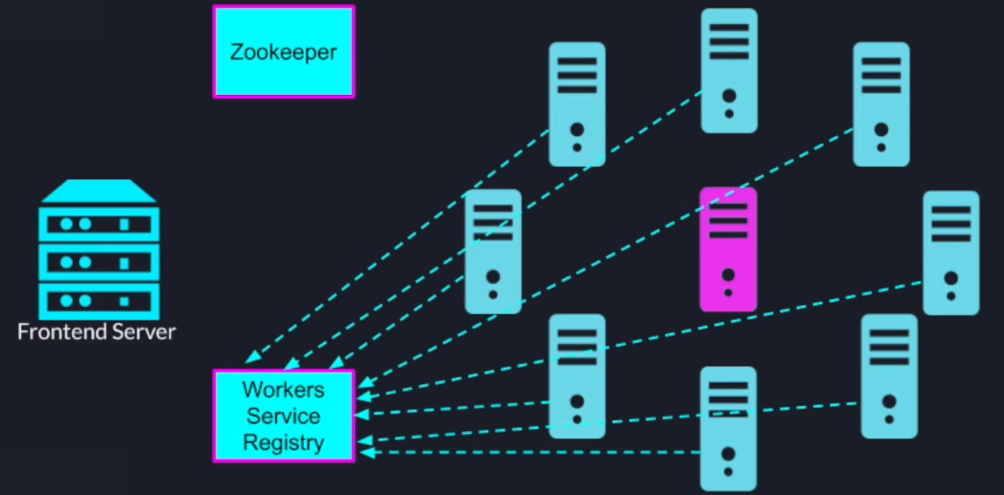
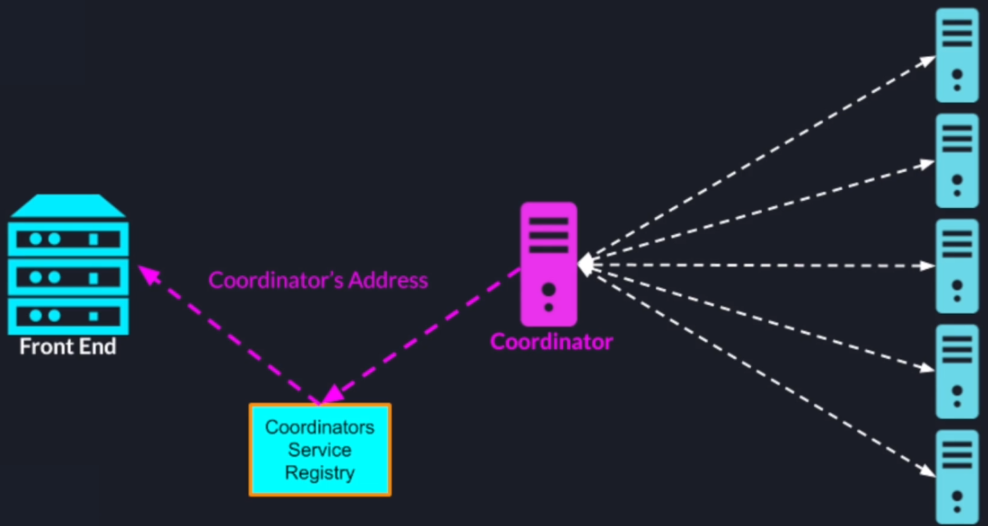
Once the roles are assigned the worker nodes will register themselves with the zookeeper based service registry
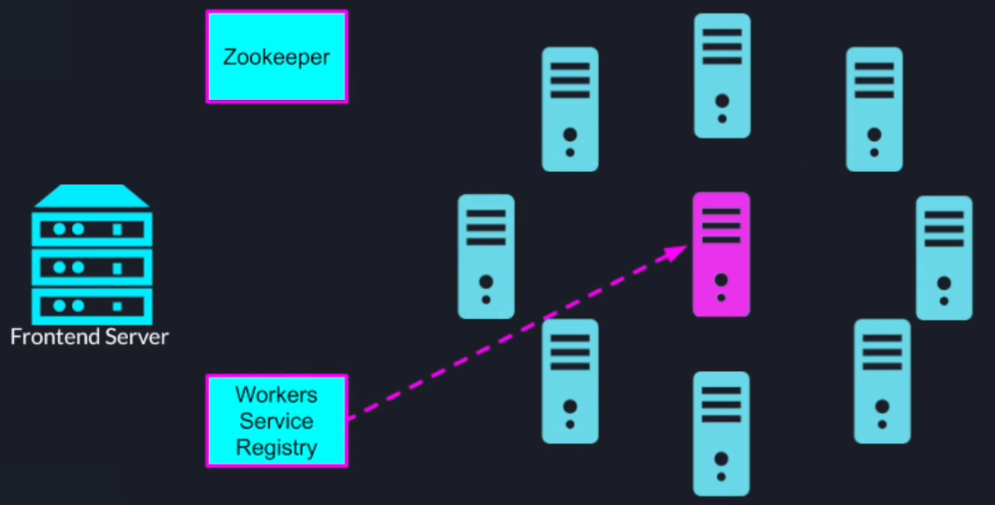
The leader will pull those addresses so it can send tasks to those worker nodes
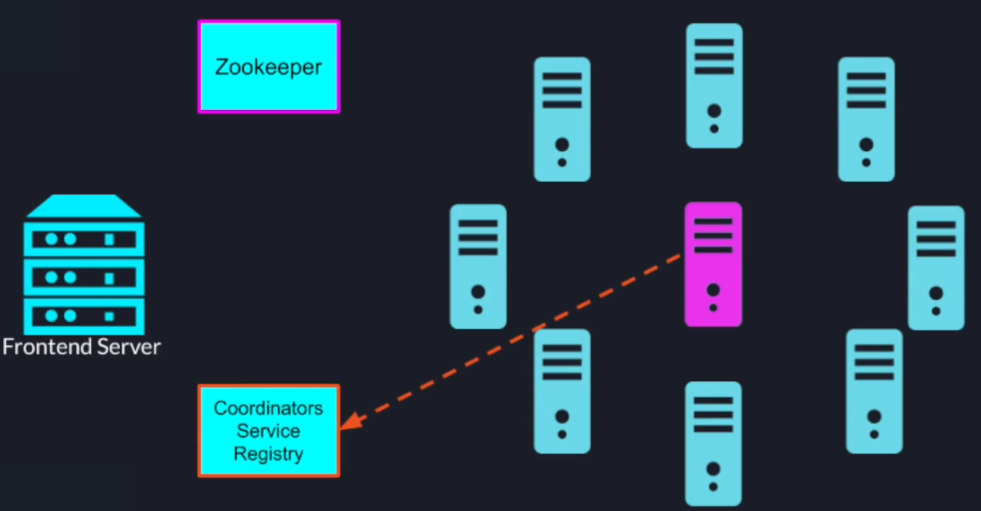
Also, the leader will register itself to a different Z node in the service registry and allow the front-end server to find his address
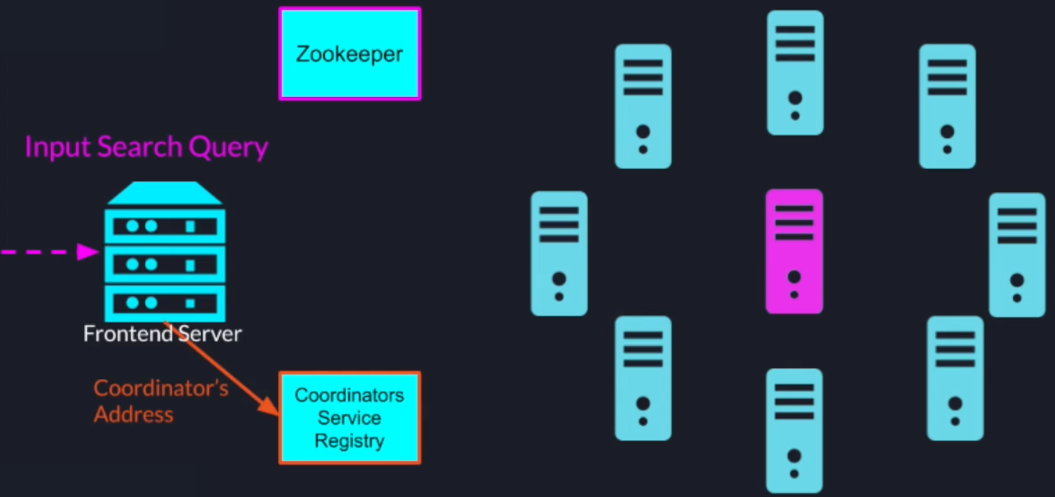
Once the search query comes as an input to our system the front-end server will look up the search coordinators address in the service registry and forward the search query to the search coordinator
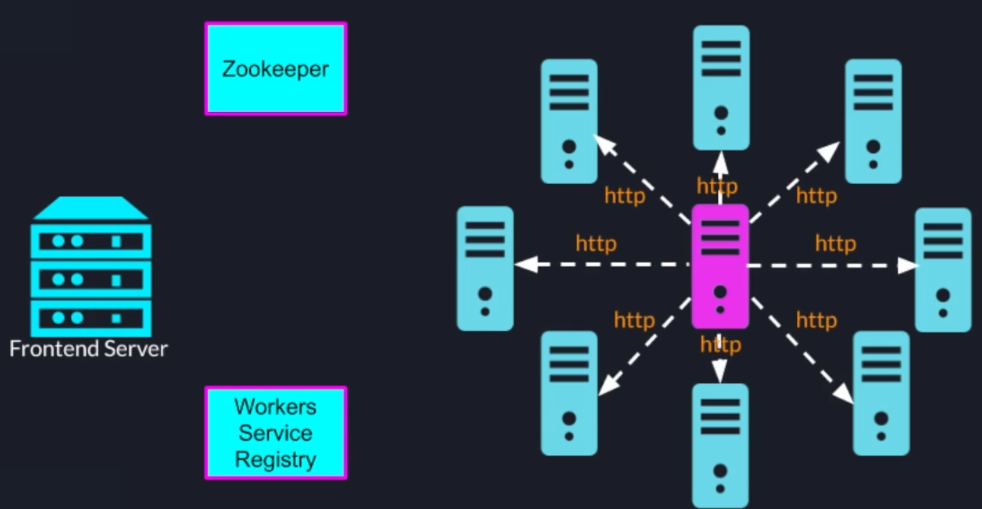
Once the coordinator receives the search query it will inspect all the currently available workers and send the tasks through HTTP to all the worker nodes
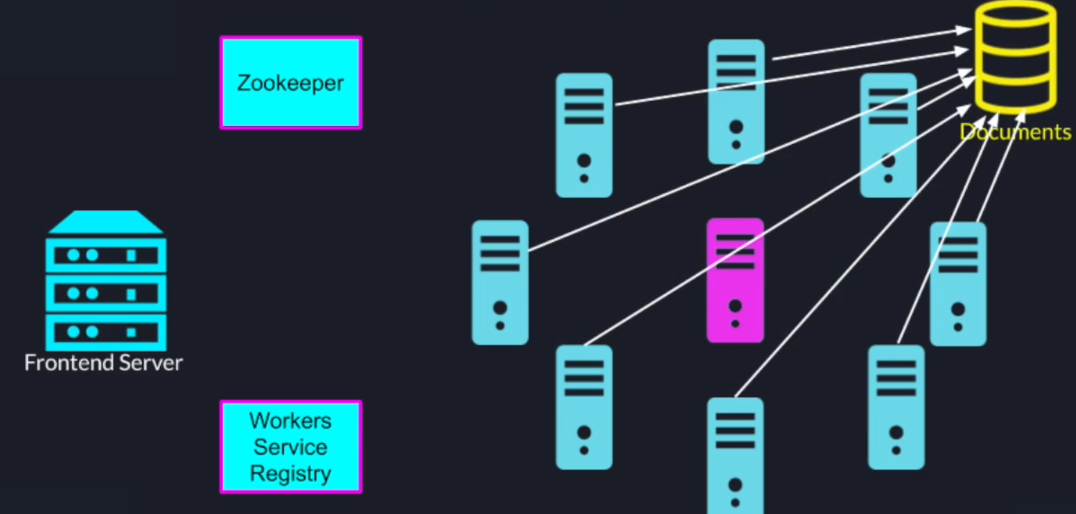
Once a node gets its allocated set of documents it will read them from the document repository and perform the calculation and send the results back to the leader
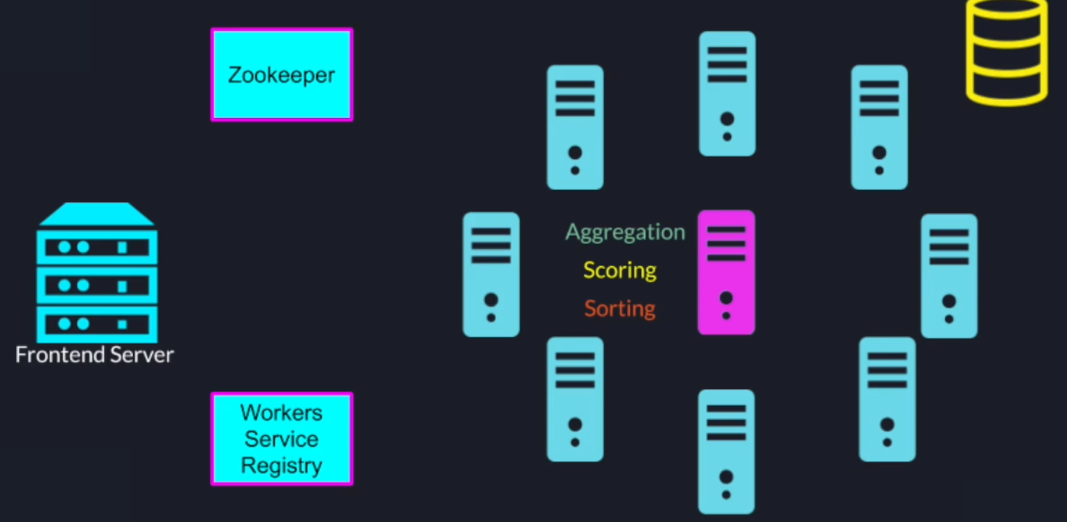
When the leader gets all the results it will perform the final aggregation scoring and sorting and send the results back to the upstream system
5. System Architecture
In the System Architecture 1, we already define the model for exchanging data between the worker nodes and the search coordinator. So now we will focus on the communication between the search cluster coordinator and the user-facing front-end server.
The message from the coordinator to the front end server is a sordid collection of all the results were received from the search nodes its size can get very big.
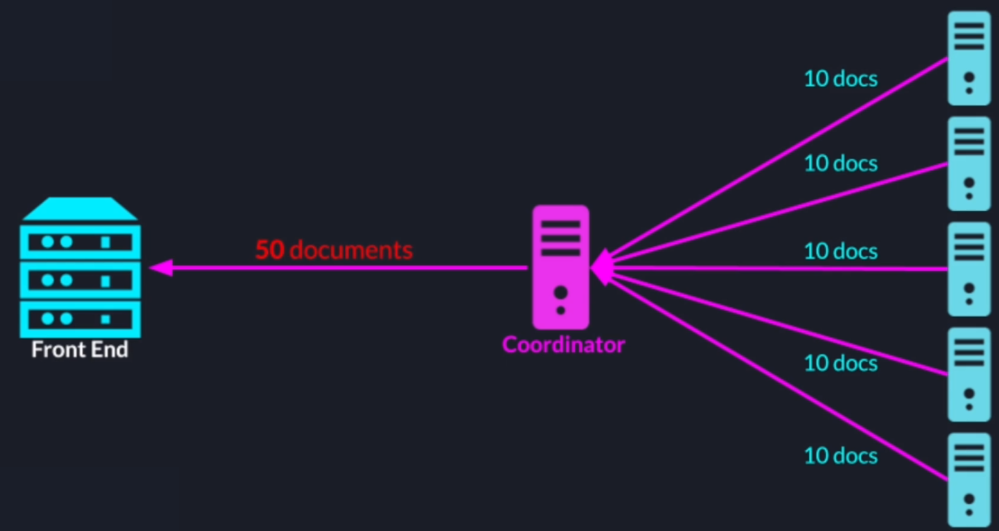
Also, the front-end server and the search cluster are completely separate code bases and separate software systems so decoupling them with an easily extendable and flexible API would be a good design choice.
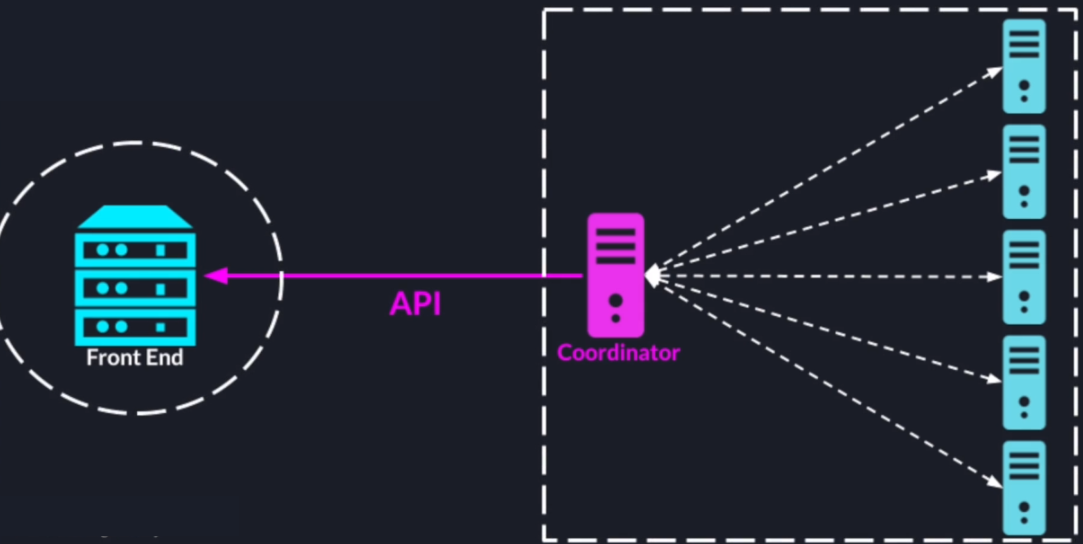
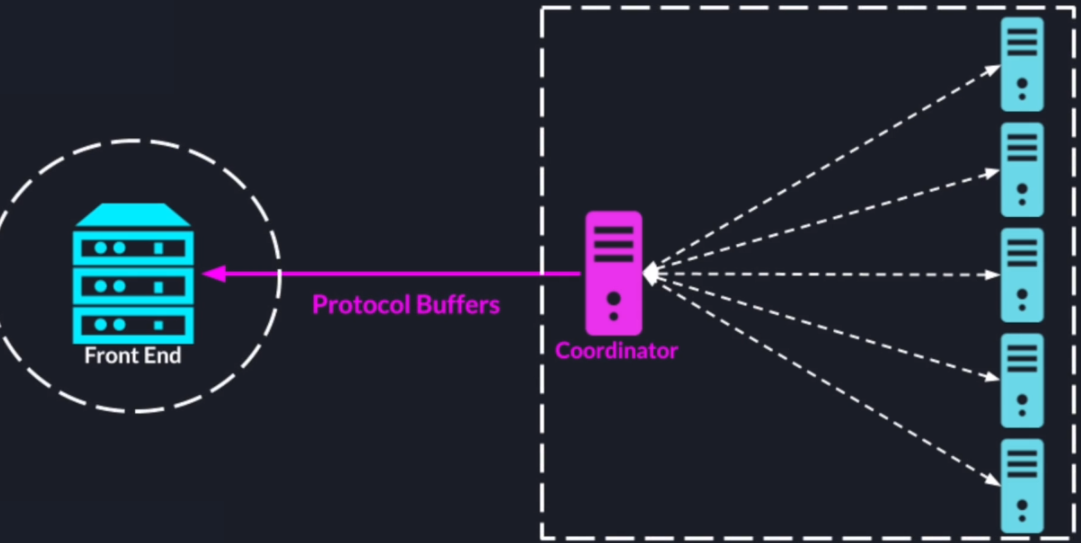
We will use the protocol buffers for serializing data between the front end and the search coordinator
Also as we mentioned in the previous lectures to communicate the address of the coordinator to the front end we'll add the additional coordinator service
6. References
https://en.wikipedia.org/wiki/Tf%E2%80%93idf
https://en.wikipedia.org/wiki/Text_corpus
https://en.wikipedia.org/wiki/Linguistics
https://en.wikipedia.org/wiki/Stop_words
https://en.wikipedia.org/wiki/Function_word
https://www.quora.com/What-is-a-tf-idf-vector
https://surferseo.com/blog/tf-idf-seo-prominent-words-phrases/
'MLAI > Preprocessing' 카테고리의 다른 글
Feature Scaling (0) 2020.01.18 Categorical Data (0) 2020.01.18 Missing Data (0) 2020.01.18