-
Categorical DataMLAI/Preprocessing 2020. 1. 18. 20:02
1. Overview
2. Description

2.1 Encode Categorical Data
Since machine learning models are based on mathematical equations you can intuitively understand that it would cause some problem if we keep the text here and the categorical variables in the equations because we would only want numbers in the equations. So that's why we need to encode the catacombs variables. That is to encode the text that we have here into numbers.
2.2 Dummy Encoding
the problem is still the same machine learning models are based on equations and that's good that we replaced the text by numbers so that we can include the numbers in the equations. However since one is greater than zero and two is greater than one the equations in the model will think that Spain has a higher value than Germany and France and Germany has a higher value than France. And that's not the case. These are actually three categories and there is no relational order between the three. We cannot compare France Spain and Germany by saying that Spain is greater than Germany or Germany is greater than France. This wouldn't make any sense if we had for example the variable size with the size like small medium and large then yes we could express orders between the values of this variable because large is greater than medium and medium is greater than smo. There he doesn't make any sense. So we have to prevent the machine learning equations from thinking that Germany is greater than France
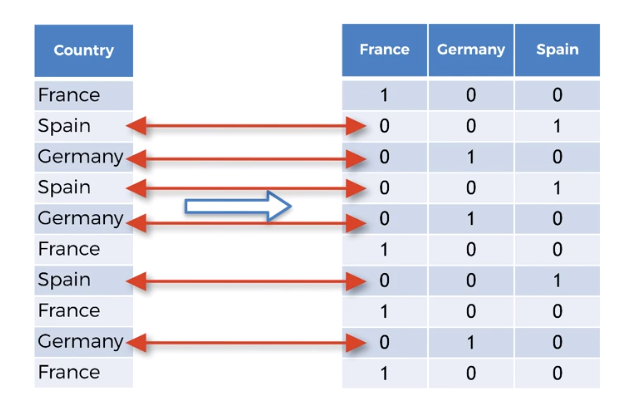
3. Omit dummy variable
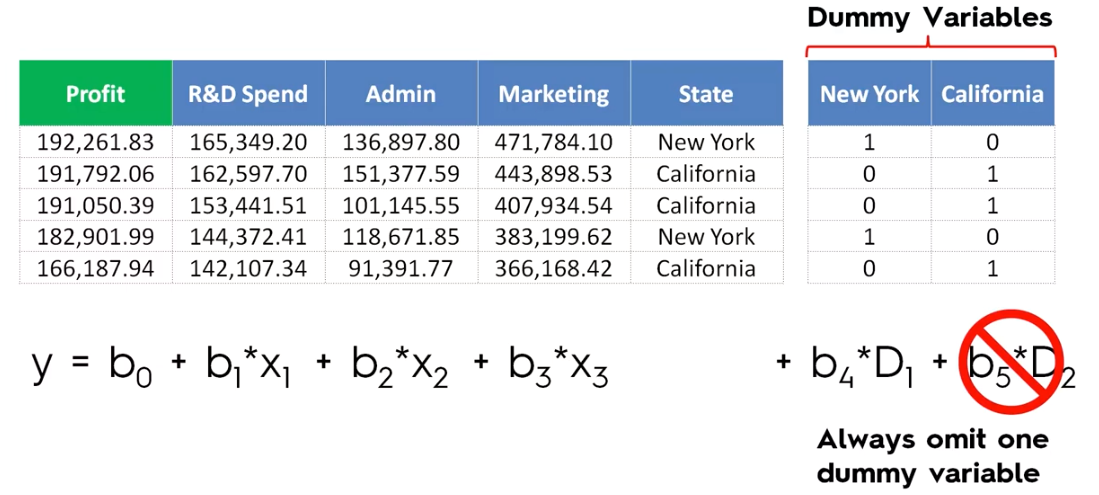
Whenever you're building a model always admit to one dummy variable and this applies irrespective of the number of dummy variables they are in that specific dummy set. If you have nine then you should only include eight if you have 100. Then you should only include 99 of them.
4. Reference
'MLAI > Preprocessing' 카테고리의 다른 글
Feature Scaling (0) 2020.01.18 Missing Data (0) 2020.01.18 Term frequency–inverse document frequency(TF-IDF) (0) 2019.09.25