-
KinesisData Engineering 2019. 9. 20. 00:42
Kinesis Data Stream
- Real-time Data Stream
- Retention between 1 day to 365 days
- Ability to reprocess (replay) data
- Once data is inserted in Kinesis, it can’t be deleted (immutability)
- Data that share the same partition goes to the same shard (ordering)
- Producers: AWS SDK, Kinesis Producer Library (KPL), Kinesis Agent
- Consumers
- Write your own: Kinesis Client Library (KCL), AWS SDK
- Managed: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
Capacity Modes
Provisioned mode
- You choose the number of shards provisioned, scale manually or use API
- Each shard gets 1 MB/s in (or 1000 records per second)
- Each shard gets 2 MB/s out (classic or enhanced fan-out consumer)
- You pay per shard provisioned per hour
On-demand mode
- No need to provision or manage the capacity
- Default capacity provisioned (4 MB/s in or 4000 records per second)
- Scales are automatically based on observed throughput peaks during the last 30 days
- Pay per stream per hour & data in/out per GB
Security

- Control access/authorization using IAM policies
- Encryption in flight using HTTPS endpoints
- Encryption at rest using KMS
- You can implement encryption/decryption of data on the client-side (harder)
- VPC Endpoints are available for Kinesis to access within VPC
- Monitor API calls using CloudTrail
Architecture
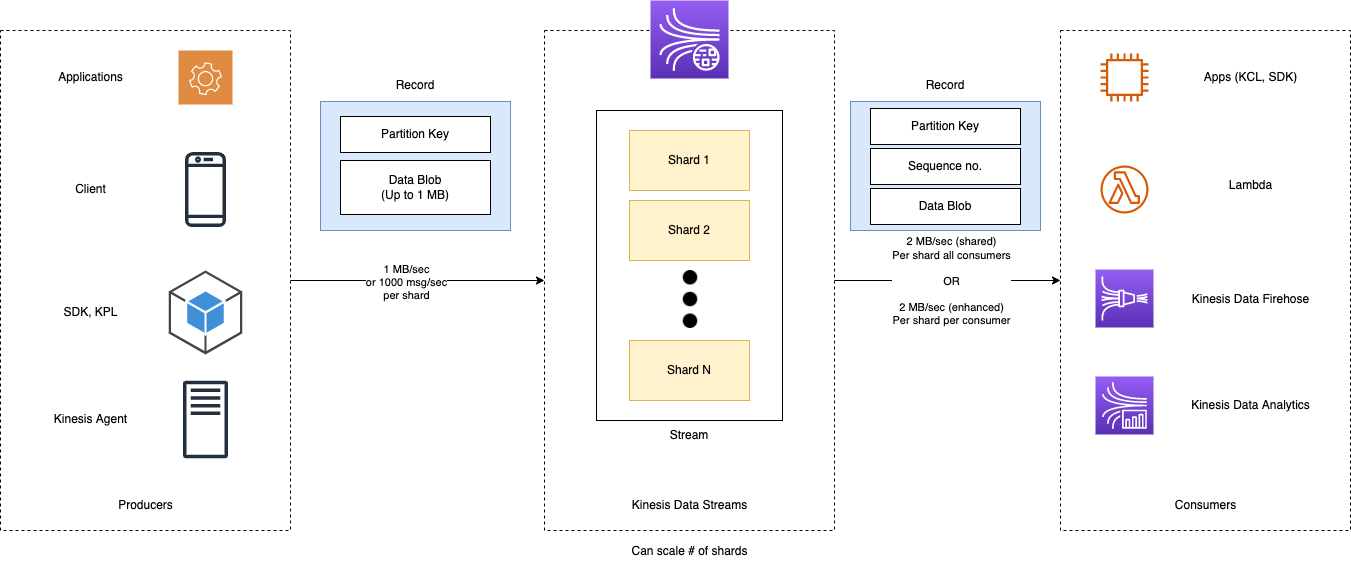
Producer
Producers send data into Kinesis Data Stream
Can be in many forms: Applications, multi-platform clients, AWS SDK, Kinesis Producer Library (KPL), Kinesis Agent, Apache Spark, Log4j Appenders, Flume, Kafka Connect, NiFi, and so on.
Record
Partition key: Define and help determine in which shard will the record go to
Data Blob: The value itself
Fan-out
1 MB/sec or 1000 msg/sec per shard. If you have 6 shards, you get 6 MB/sec or 6000 msg/sec
Kinesis Data Streams
Kinesis Data Stream is made of multiple shards
Shards
- Shards are numbered
- Define data stream capacity in terms of ingestion and consumption rates
Consumer
Many forms: Applications, SDK, Kinesis Client Libraries, Lambda, Kinesis Data Firehose, Kinesis Data Analysis
Record
Partition key: Define and help determine in which shard will the record go to
Sequence number: Represent where a record was in the shard
Data Blob: The value itself
Fan-out
- 2 MB/sec (shared) per shard for all consumers
- 2 MB/sec (enhanced) Per shard per consumer
Kinesis Producer SDK - PutRecord(s)
- APIs that are used PutRecord (one) and PutRecords (many records)
- PutRecords uses batching and increases throughput → less HTTP requests
- ProvisionedThroughputExceeded if we go over the limits
-
- AWS Mobile SDK: Android, IOS, and etc
- Use case: low throughput, higher latency, simple API, AWS Lambda
- Managed AWS sources for Kinesis Data Streams:
- CloudWatch Logs
- AWS IoT
- Kinesis Data Analytics
AWS Kinesis API - Exceptions
ProvisionedThroughputExceeded Exceptions
- Happens when sending more data (exceeding MB/s or TPS for any shard)
- Make sure you don’t have a hot shard (such as your partition key is bad and too many data goes to that partition)
Solution
- Retries with backoff
- Increase shards (scaling)
- Ensure your partition key is a good one
Kinesis Producer Library (KPL)
- Easy to use and highly configurable C++/Java library
- Used for building high-performance, long-running producers
- Automated and configurable retry mechanism
- Synchronous and Asynchronous API (better performance for async)
- Submits metrics to CloudWatch for monitoring
- Batching (both turned on by default) - increase throughput, decrease cost:
- Collect: Records and Write to multiple shards in the same PutRecords API call
- Aggregate: increased latency
- Capability to store multiple records in one record (go over 1000 records per second limit)
- Increase payload size and improve throughput (maximize 1 MB/s limit)
- Compression must be implemented by the user
- KPL Records must be de-coded with KCL or a special helper library
Batching

- A record is not going to be sent right away, but aggregate several records into one record
- Several aggregated records also are collected and sent by one PutRecords
- We can influence the batching efficiency by introducing some delay with RecordMaxBufferedTime (default 100ms)
When not to use
- The KPL can incur an additional processing delay of up to RecordMaxBufferedTime within the library (user-configurable)
- Larger values for RecordMaxBufferedTime results in higher packing efficiencies and better performance
- Applications that cannot tolerate this additional delay may need to use the AWS SDK directly
Kinesis Agent
- Monitor Log files and sends them to Kinesis Data Streams
- Java-based agent, built on top of KPL
- Install in Linux-based server environments
Features
- Write from multiple directories and write to multiple streams
- Routing feature based on directory / log file
- Pre-process data before sending to streams (single line, csv to json, log to json, and so on)
- The agent handles file rotation, checkpointing, retry upon failures
- Emits metrics to CloudWatch for monitoring
Kinesis Consumer SDK - GetRecords
- Classic Kinesis - Records are polled by consumers from a shard
- Each shard has 2 MB total aggregate throughput
- GetRecords returns up to 10 MB of data (then throttle for 5 seconds) or up to 10000 records
- Maximum of 5 GetRecords API calls per shard per second = 200 ms latency
- If 5 consumers application consume from the same shard, means every consumer can poll once a second and receive less than 400 KB/s
Kinesis Client Library (KCL)

- Java-first library but exists for other languages too (Golang, Python, Ruby, Node, .Net, and so on)
- Read records from Kinesis produced with the KPL (de-aggretation)
- Share multiple shards with multiple consumers in one group, shard discovery
- Checkpoint feature to resume progress
- Leverage DynamoDB for coordination and checkpointing (one row per shard)
- Make sure you provision enough Write Capacity Unit(WCU) / Read Capacity Unit (RCU)
- Or use On-Demand for DynamoDB
- Otherwise DynamoDB may slow down KCL
- Record processors will process the data
- ExpiredIteratorException → increase WCU
Kinesis Connector Library

- Older Java library (2016(, leverage the KCL library
- Write data to:
- S3
- DynamoDB
- Redshift
- ElasticSearch
- Kinesis Firehose replaces the Connector Library for a few of these targets, Lambda for the others
Lambda sourcing from Kinesis
- Lambda can source records from Kinesis Data Streams
- Lambda consumer has a library to de-aggregate record from the KPL
- Lambda can be used to run lightweight ETL to:
- S3
- DynamoDB
- Redshift
- ElasticSearch
- Anywhere you want
- Lambda can be used to trigger notifications / send emails in real time
- Lambda has a configurable batch size (more in Lambda section)
Kinesis Enhanced Fan Out
- New game-changing feature from August 2018
- Works with KCL 2.0 and AWS Lambda (Nov 2018)
- Each Consumer get 2 MB/s of provisioned throughput per shard
- That means 20 consumers will get 40 MB/s per shard aggregated
- No more 2 MB/s limit
- Enhanced Fan Out: Kinesis pushes data to consumers over HTTP
- Reduce latency (~70 ms)
Comparison Enhanced Fan-Out and Standard Consumers
Standard consumers
- Low number of consuming applications (1, 2, 3, …)
- Can tolerate ~200 ms latency
- Minimize cost
Enhanced Fan-Out Consumers
- Multiple Consumer applications for the same Stream
- Low Latency requirement ~ 70 ms
- Higher costs
- Default limit of 5 consumers using enhanced fan-out per data stream
Kinesis Scaling
Kinesis Operations - Adding Shards

- Also called “Shard Splitting”
- Can be used to increase the Stream capacity (1 MB/s data in per shard)
- Can be used to divide a “hot shard”
- The old shard is closed and will be deleted once the data is expired
Kinesis Operations - Merging Shards

- Decrease the Stream capacity and save costs
- Can be used to group two shards with low traffic
- Old shards are closed and deleted based on data expiration
Out-of-order records after resharding

- After a reshard, you can read from child shards
- However, data you haven’t read yet could still be in the parent
- If you start reading the child before completing reading the parent, you could read data for a particular hash key out of order
- After a reshard, read entirely from the parent until you don’t have new records
- Note: The Kinesis Client Library (KCL) has this logic already built-in, even after resharding operations
Kinesis Operations - Auto Scaling

- Auto Scaling is not a native feature of Kinesis
- The API call to change the number of shards is UpdateShardCount
- We can implement Auto Scaling with AWS Lambda
- https://aws.amazon.com/blogs/big-data/scaling-amazon-kinesis-data-streams-with-aws-application-auto-scaling/
Kinesis Scaling Limitations
- Resharding cannot be done in parrallel. Plan capacity in advance
- You can only perform one resharding operation at a time and it takes a few seconds
- For 1000 shards, it takes 30K seconds (8.3 hours) to double the shards to 2000
You can’t do the following:
- Scale more than 10x for each rolling 24-hour period for each stream
- Scale up to more than double your current shard count for a stream
- Scale down below half your current shard count for a stream
- Scale up to more than 500 shards in a stream
- Scale a stream with more than 500 shards down unless the result is fewer than 500 shards
- Scale up to more than the shard limit for your account
Handling Duplicates
Producer-side

- Producer retries can create duplicates due to network timeouts
- Although the two records have identical data, they also have unique sequence numbers
- Fix: embed unique record ID in the data to de-duplicate on the consumer side
Consumer-side
- Consumer retries can make your application read the same data twice
- Consumer retries happen when record processors restart:
- A worker terminates unexpectedly
- Worker instances are added or removed
- Shards are merged or split
- The application is deployed
- Fixes:
- Make your consumer application idempotent
- If the final destination can handle duplicates, it’s recommended to do it there
- https://docs.aws.amazon.com/streams/latest/dev/kinesis-record-processor-duplicates.html
Kinesis Security
- Control access / authorization using IAM policies
- Encryption in flight using HTTPS endpoints
- Encryption at rest using KMS
- Client side encryption must be manually implemented (harder)
- VPC Endpoints available for Kinesis to access with VPC
Kinesis Data Firehose

- Fully Managed Service, no administration
- Near Real Time (60 seconds latency minimum for non full batches)
- Load data into RedShift / S3 / ElasticSearch / Splunk
- Automatic scaling
- Supports many data formats
- Data Conversions from JSON to Parquet / ORC (only for S3)
- Data Transformation through AWS Lambda (ex: CSV → JSON)
- Supports compression when target is Amazon S3 (GZIP, ZIP, and SNAPPY)
- Only GZIP is the data is further loaded into Redshift
- Pay for the amount of data going through Firehose
- Spark / KCL do not read from KDF
Kinesis Data Firehose Delivery Diagram

- There’s a bunch of blueprints available for AWS Lambda to try to help you transform the data in Firehose in the format you want
- If Redshift is your destination, actually it goes through S3, and then there will be a COPY command issued to put that data into Redshift
- You don’t lose data with Kinesis Data Firehose
- either it ends in your targets
- you will have a recollection of all the transformation failure, the delivery failure, and even the source records if you want it to into another S3 bucket
Firehose Buffer Sizing
- Firehose accumulates records in a buffer
- The buffer is flushed based on time and size rules
- Buffer Size (ex:32 MB): if that buffer size is reached, it’s flushed
- Buffer Time (ex: 2 minutes): if that time is reached, it’s flushed
- Firehose can automatically increase the buffer size to increase throughput
- Hight throughput → Buffer Size will be hit
- Low throughput → Buffer Time will be hit
Kinesis Data Stream vs Firehose
Streams
- Going to write custom code (producer/consumer)
- Real time (~200 ms latency for classic, ~70 ms latency for enhanced fan-out)
- Must manage scaling (shard splitting/merging)
- Data Storage for 1 to 365 days, replay capability, multi consumers
- Use with Lambda to insert data in real-time to ElasticSearch (for example)
Firehose
- Fully managed, send to S3, Splunk, Redshift, ElasticSearch
- Serverless data transformations with Lambda
- Near real time (lowest buffer time is 1 minute)
- Automated Scaling
- No data Storage
CloudWatch Logs Subscriptions Filters
CloudWatch Logs Subscription Filter Patterns Near Real-Time into Amazon ES

CloudWatch Logs Subscription Filter Patterns Real Time Load into Amazon ES

CloudWatch Logs Subscription Filter Patterns Real Time Analytics into Amazon ES

'Data Engineering' 카테고리의 다른 글
AWS MSK (0) 2022.07.01 Collection Introduction (0) 2022.06.29 Data Format (0) 2022.06.17 Apache Airflow (0) 2022.06.06 Apache Kafka (0) 2019.09.05