-
Apache AirflowData Engineering 2022. 6. 6. 11:32
Introduction
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows. Airflow is an orchestrator allowing you to execute your tasks at the right time, in the right way, in the right order.
Airflow allows you to create a data pipeline that will interact with many different tools so that you can execute your tasks at the right time, in the right way, and in the right order.
With airflow, you will be able to manage your data pipelines and execute your tasks in a very reliable way and you will be able to monitor and try your tasks automatically.
Benefits
Python
They are coded in python. everything that can do in python, you can do it in your data pipelines. So the possibilities are quite limitless at the end.
Scalability
You can execute as many tasks as you want in parallel. Obviously, it depends on your architecture, on your resources. For example, if you have a Kubernetes cluster, you will be able to execute your tasks using that Kubernetes cluster.
GUI
You will be able to monitor your data problems from it. You will be able to retry your tasks. You will be able to interact a lot from the user interface of airflow with your data pipelines.
Extensibility
If there is a new tool and you want to interact with that new tool, you don’t have to wait for airflow to be upgraded. You can create your own plugin added to your app, for instance, and you will be able to interact with that new tool
Core Components
- Web server: Flask server with Gunicorn serving the UI
- Scheduler: Daemon is in charge of scheduling workflows
- Metastore: Database where metadata is stored
- Executor: Class defining how your tasks should be executed
- Worker: Process/sub process executing your task
Concepts
DAG

Directed acyclic graph. A DAG is a data pipeline.
Operator
Wrapper around the task
#Operator db = connect(host, credentials) db.insert(sql_request)- Action Operator: Actually executing functions or commands such as batch operator, python operator
- Transfer Operator: Allow you to transfer data between a source and a destination such as prestoToMysql operator
- Sensor Operator: Differ than the other operators as they wait for something to happen before moving to the next task such as file sensor
Task
It is an operator in your data pipeline
Task Instance
As soon as you trigger your data pipeline and so your tasks, that task become task instance. So as soon as you execute an operator, that operator becomes a task instance.
Workflow
A DAG is triggered and has the operators with one dependency corresponding to your DAG, that is a concept of workflow. So the workflow is a DAG with operators, tasks, with dependencies.
What Airflow is not?
Not a data streaming solution such as Apache Flink neither a data processing framework such as spark
Architecture
One Node Architecture
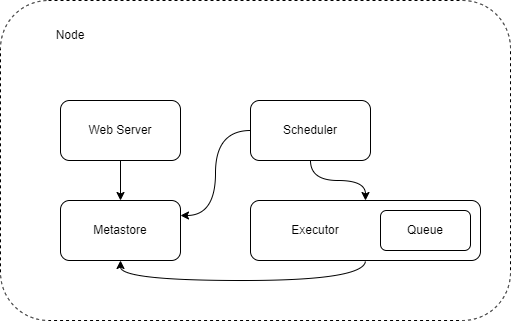
- The web server will fetch some metadata coming from the Metastore
- Then the scheduler will be able to talk with the Metastore
- The executor in order to send tasks that you want to execute
- And the executor will update the status of the tasks in the Metastore
- Those components talk together through the Metastore
- The executor allows you to define how your tasks will be executed
- Queue is used in order to define the order in which your tasks will be executed
- The queue is part of the executor
Multi Nodes Architecture (Celery)

- The queue is actually external to the executor, not like in single node architecture
- You have multiple nodes, multiple machines where on each machine you will have airflow worker running
- As usual, Web server fetches some metadata from the Metastore and the status of your tasks
- Then you have the scheduler talking to the Metastore as well as the executor in order to scheduler the tasks
- The executor will push the tasks that you want to trigger in the queue
- One your tasks are in the queue, the airflow workers will fetch those tasks and will execute them on their own machine
How it works

- New pipeline py will be added into Folder Dags
- Both Web server and scheduler will parse the folder dags in order to be aware of your new data pipeline
- As soon as your data pipeline is ready to be triggered, a DagRun Object is created in Metastore
- Dagrun object has a state of running in Metastore
- The first task is scheduled
- When a task is ready to be triggered in your data pipeline, you have a task instance object
- Executor runs task instance and updates the task instance’s object, the status of the task in the Metastore
- Once your task has been done, update state in Metastore and scheduler check it and Web server upate UI
Reference
'Data Engineering' 카테고리의 다른 글
AWS MSK (0) 2022.07.01 Collection Introduction (0) 2022.06.29 Data Format (0) 2022.06.17 Kinesis (0) 2019.09.20 Apache Kafka (0) 2019.09.05