-
Apache KafkaData Engineering 2019. 9. 5. 01:33
1. Overview
Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open-sourced by LinkedIn in 2011, Kafka has quickly evolved from messaging queue to a full-fledged event streaming platform.
Founded by the original developers of Apache Kafka, Confluent delivers the most complete distribution of Kafka with Confluent Platform. Confluent Platform improves Kafka with additional community and commercial features designed to enhance the streaming experience of both operators and developers in production, at a massive scale.

1.1 Features
- Open-source
- Provides distributed queuing
- Publish/Subscribe
- High scalability
- Fault tolerance
1.2 Data Persistence in Kafka
- Kafka persists all its messages on disk
- Even after messages are consumed by the consumers, the records still stay within Kafka for a configurable period of time
- Persistence allows new consumers to join and consumer older messages
- Consumers that failed in the process of reading/processing a message to retry
- Failed Brokers can recover very fast
2. Description
2.1 Producer Record

2.2 Basic Components
2.2.1 Topics
- A particular stream of data
- Similar to a table in a database without all the constraints
- You can have as many topics as you want
- A topic is identified by its name
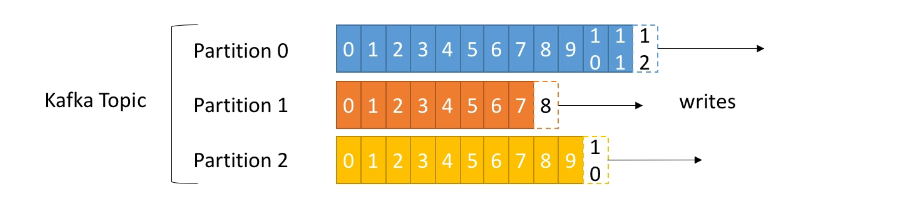
2.2.2 Partitions
- Topic partitioning allows us to scale a topic horizontally
- More partitions in a topic, higher parallelism
- Each partition is ordered
- Each message within a partition gets an incremental id, called offset
- Thanks to the partitioning of a Topic, we can have many broker instances working in parallel to handle incoming messages

A hash function is applied on the record's key and that determines where that record would go.
2.2.3 Offset
- Only have a meaning for a specific partition
- offset 3 in partition 0 doesn't represent the same data as offset 3 in partition 1
2.2.4 Notes
- Order is guaranteed only within a partition, but not across partitions
- Data is kept only for a limited time - default 1 week
- Once the data is written to a partition, it can't be changed - immutability
- Data is assigned randomly to a partition unless a key is provided
2.3 Brokers
- A Kafka cluster is composed of multiple brokers, in other words, servers
- Each broker is identified with its ID which is an integer
- Each broker contains certain topic partitions, but not all the data. So distributed
- After connecting to any broker which is called a bootstrap broker, you will be connected to the entire cluster

2.4 Topic Replication
2.4.1 Topic replication factor
- Topics should have a replication factor > 1. Usually between 2 and 3
- For each partition, only one broker acts as a partition leader, other brokers are partition followers
- The leader takes all the reads and writes
- The followers replicate the partition data to stay in sync with the leader
- This way if a broker is down, another broker can serve the data

2.4.2 Concept of Leader for a Partition
- At any time only One broker can be a leader for a given partition
- Only that leader can receive and serve data for a partition
- The other brokers will synchronize the data
- Therefore each partition has one leader and multiple ISR (in-sync replica)

2.5 Producers
- Producers write data to topics which are made of partitions
- Producers automatically know to which broker and partition to write to
- In the case of Broker failures, Producers will automatically recover

2.5.1 Acknowledgment
- acks=0: Producer won't wait for acknowledgment - Possible data loss
- acks=1: Producer will wait for leader acknowledgment - limited data loss
- acks=all: Leader + replicas acknowledgement - no data loss
2.5.2 Message keys
- Producers can choose to send a key with the message such as string, number, etc.
- If key = null, data is sent round-robin - broker 101 then 102 then 103 and so on
- If a key is sent, then all message for that key will always go to the same partition
- A key is basically sent if you need message ordering for a specific field

2.6 Consumers
- Consumers read data from a topic identified by name
- Consumers know which broker to read from
- In the case of broker failures, consumers know how to recover
- Data is read in order within each partition, but parallel when it comes to across the partitions

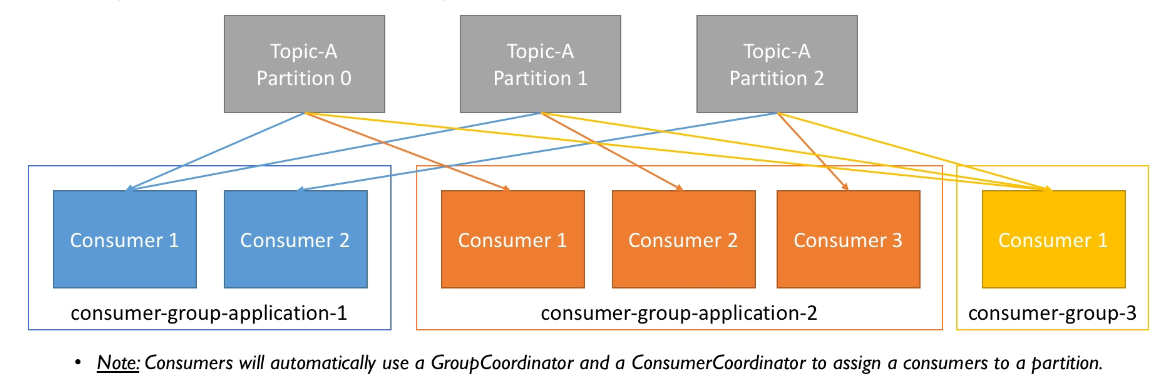
2.6.1 Consumer Groups
- Consumers read data in consumer groups
- Each consumer within a group read from exclusive partitions
- If you have more consumers than partitions, some consumers will be inactive
- Having many consumers, consuming in parallel from the same topic


2.7 Consume Message

In order for an application instance to consume messages from a Kafka topic, a consumer has to belong to a consumer group. When consumers subscribe to a topic each message is delivered to a single instance in a consumer group.
2.7.1 Kafka as a Distributed Queue
Processing of the published messages is complex we can place multiple consumer instances in a group and the messages to our topic will be load-balanced among all the consumers within that group

2.7.2 Kafka as a Publish/Subscribe System
If we want to use Kafka as a publish/subscribe messaging system we can place each consumer in a different consumer group which means every message published or topic will be delivered to all the consumers.

2.6.2 Consumer Offsets
- Kafka stores the offsets at which a consumer group has been reading
- The offsets committed live in a Kafka topic named __consumer_offsets
- When a consumer in a group has processed data received from Kafka, it should be committing the offsets
- If a consumer dies, it will be able to read back from where it left off thanks to the committed consumer offsets

2.6.3 Delivery semantics for consumers
A consumer chooses when to commit offsets. There are 3 delivery semantics
- At most once
- Offsets are committed as soon as the message is received
- If the processing goes wrong, the message will be lost and won't be read again
- At least once
- Offsets are committed after the message is processed
- If the processing goes wrong, the message will be read again
- This can result in duplicate processing of messages. Make sure your processing is idempotent which means multiple processing won't impact your systems
- Exactly once
- Can be achieved for Kafka
- Kafka workflows using Kafka Streams API
- For Kafka to External system workflows, use an idempotent consumer
2.7 Kafka Broker Discovery
- Every Kafka broker is also called a bootstrap server
- You only need to connect to one broker and you will be connected to the entire cluster
- Each broker knows about all brokers, topics, and partitions which means metadata

2.8 Zookeeper
- Zookeeper manages brokers and keeps a list of them
- Zookeeper helps in performing leader election for partitions
- Zookeeper sends notifications to Kafka in the case of changes e.g. new topic, broker dies, broker comes up, delete topics, etc.
- Kafka can't work without Zookeeper
- Zookeeper by design operates with an odd number of servers such as 3, 5, 7
- Zookeeper has a leader which handle writes, the rest of the servers are followers which handle reads
- Zookeeper does not store consumer offsets with Kafka > v0.10

2.9 Kafka Guarantees
- Messages are appended to a topic-partition in the order they are sent
- Consumers read messages in the order stored in a topic-partition
- With a replication factor of N, producers and consumers can tolerate up to N -1 brokers being down
- This is why a replication factor of 3 is a good idea
- Allows for one broker to be taken down for maintenance
- Allows for another broker to be taken down unexpectedly
- This is why a replication factor of 3 is a good idea
- As long as the number of partitions remains constant for a topic which means no new partitions, the same key will always go to the same partition
3. Karka Partitioning Example - Online Store

Purchases from different users are not related to each other so maintaining the order of those events may not be very important so we can use the user ID as the key for the record. This way we can spread all the purchasing events across all the partitions.
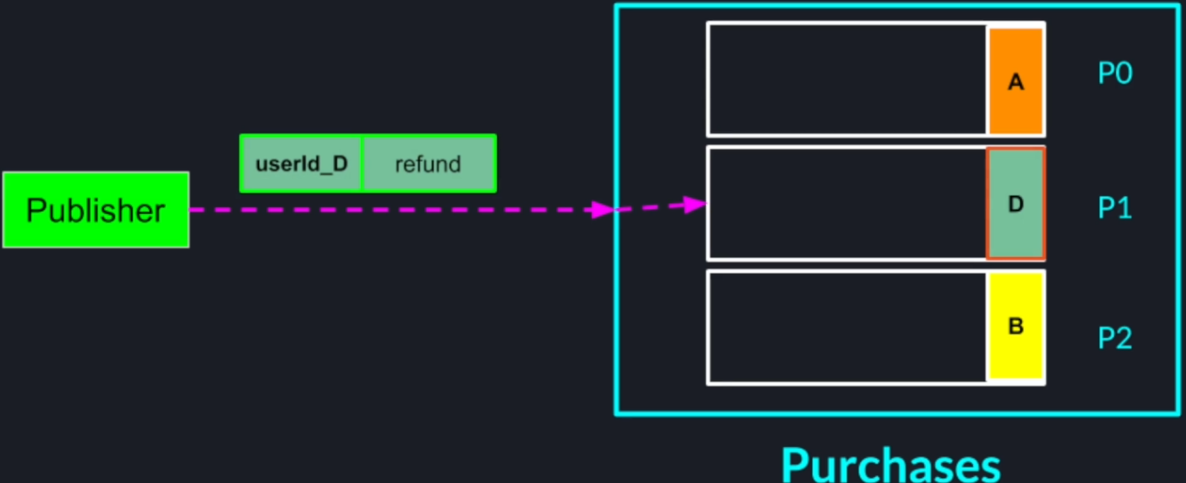
On the other hand, the order of events from the same user is important. For example, a user may purchase an item and then immediately ask for a refund for the same item and because the key which is the user ID for both messages is the same the records for both those events will go to the same partition and will be consumed in the correct order.
5. Apache Kafka as a Distributed System
5.1 Topic running on a single machine

Even the implementation of a message broker would be to have a single instance managing a topic running on a single machine in this approach aside from the message broker being a single point of failure. There's no way to horizontally scale our topic the message brokers parallelism is limited by the number of course on the machine and the entire topic has to fit on a single computer's memory. That's why Kafka allows us to divide a topic into multiple partitions instead of just having one monolithic topic
5.2 Distribute a topic across multiple machines

Instead of just having one monolithic topic, this way we can launch more broker instances on separate machines and distribute a topic across those brokers by splitting the partition ownership equally among them. Of course, we lose the global ordering of the messages within the topic and have to compromise on ordering only within each partition that is a trade-off we pay for achieving high scalability
5.2.1 Notes
- Number of partitions in a topic is likely maximum unit of parallelism for a Kafka Topic
- We can estimate the right number of partitions for a topic given expected our peak message rage/volume
- By adding more message brokers we can increase the Kafka topics capacity, transparently to the publishers
6. Kafka Cluster Architecture

Complete Kafka cluster consists of one or more Kafka servers all those servers need to connect to a zookeeper cluster that manages the Kafka membership leadership/partitions.
6.1 Bootstrap Kafka Servers

In order for the publishers and the consumers to connect our Kafka cluster, they only need a small subset of Kafka server addresses which are referred to as bootstrap servers the subsets can even consist of a single server.

Once the connection with those bootstrap servers has established the producers and the consumers can send and receive messages to and from the entire Kafka cluster.
7. Reference
https://medium.com/@stephane.maarek/how-can-i-learn-confluent-kafka-fb6a453defc
https://www.confluent.io/blog/upgrading-apache-kafka-clients-just-got-easier/
https://kafka.apache.org/documentation/#producerconfigs
https://kafka.apache.org/documentation/#consumerconfigs
https://blog.cloudflare.com/squeezing-the-firehose/
https://medium.com/@criccomini/how-to-paint-a-bike-shed-kafka-topic-naming-conventions-1b7259790073
https://www.datadoghq.com/blog/monitoring-kafka-performance-metrics/
https://docs.confluent.io/current/kafka/monitoring.html
https://kafka.apache.org/documentation/#monitoring
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=27846330
https://engineering.salesforce.com/mirrormaker-performance-tuning-63afaed12c21
https://community.cloudera.com/t5/Community-Articles/Kafka-Mirror-Maker-Best-Practices/ta-p/249269
https://eng.uber.com/ureplicator/
https://www.altoros.com/blog/multi-cluster-deployment-options-for-apache-kafka-pros-and-cons/
'Data Engineering' 카테고리의 다른 글
AWS MSK (0) 2022.07.01 Collection Introduction (0) 2022.06.29 Data Format (0) 2022.06.17 Apache Airflow (0) 2022.06.06 Kinesis (0) 2019.09.20