-
Decision TreeMLAI/Classification 2020. 1. 21. 16:55
1. Overview
A decision tree is a decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.
Decision trees are commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal, but are also a popular tool in machine learning.
It's a qualitative classifier
2. Description

CART (classification and regression tree)
2.1 Classification Trees
Classification trees help you classify your data so they won't give categorical variables such as male or female apple or orange or different types of colors and variables of that sort.
The analysis is when the predicted outcome is the class (discrete) to which the data belongs.

2.2 Regression Trees
Regression trees they are designed to help you predict outcomes which can be real numbers so, for instance, the salary of a person or the temperature that's going to be outside and things like that
The analysis is when the predicted outcome can be considered a real number (e.g. the price of a house, or a patient's length of stay in a hospital).
2.3 Components
2.3.1 Root

2.3.2 Internal Nodes
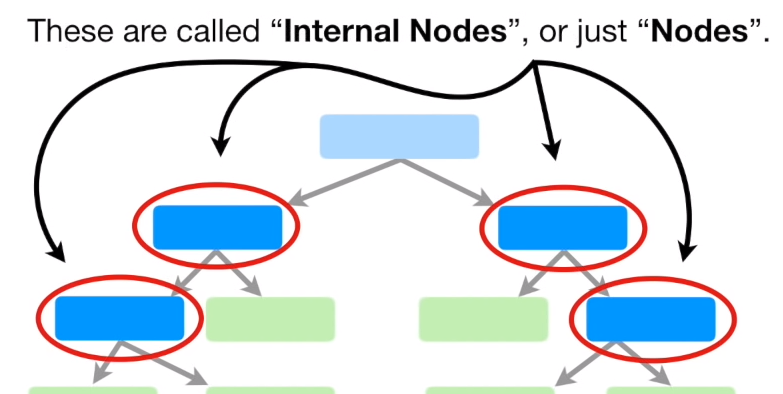
Internal nodes have arrows pointing to them and have arrows pointing away from them
2.3.3 Leaf nodes

3. Decision Tree Intuition

Split is done in such a way to maximize the number of a certain category in each of these splits so to maximize For instance we want maximum red categories and then the next split maximizes the number of green and red. The split is trying to minimize entropy.

The point is that decision trees are though a very simple tool. They aren't very powerful on their own but they're used in other methods that leverage their simplicity and create some very powerful machine learning algorithms and such algorithms even are used to perform facial recognition like on your iPhone you get you have facial recognition and also some games such as Kinect which is kind of like the we but you can play it without actually holding a control. So it's like a game for your addition to your X-Box and you can play as we followed to have any control controlling your hands so it kind of recognizes where you're moving your arms and legs and that method Microsoft decided to use around forests for that method and run it for us in Boak decision trees.
4. Learning
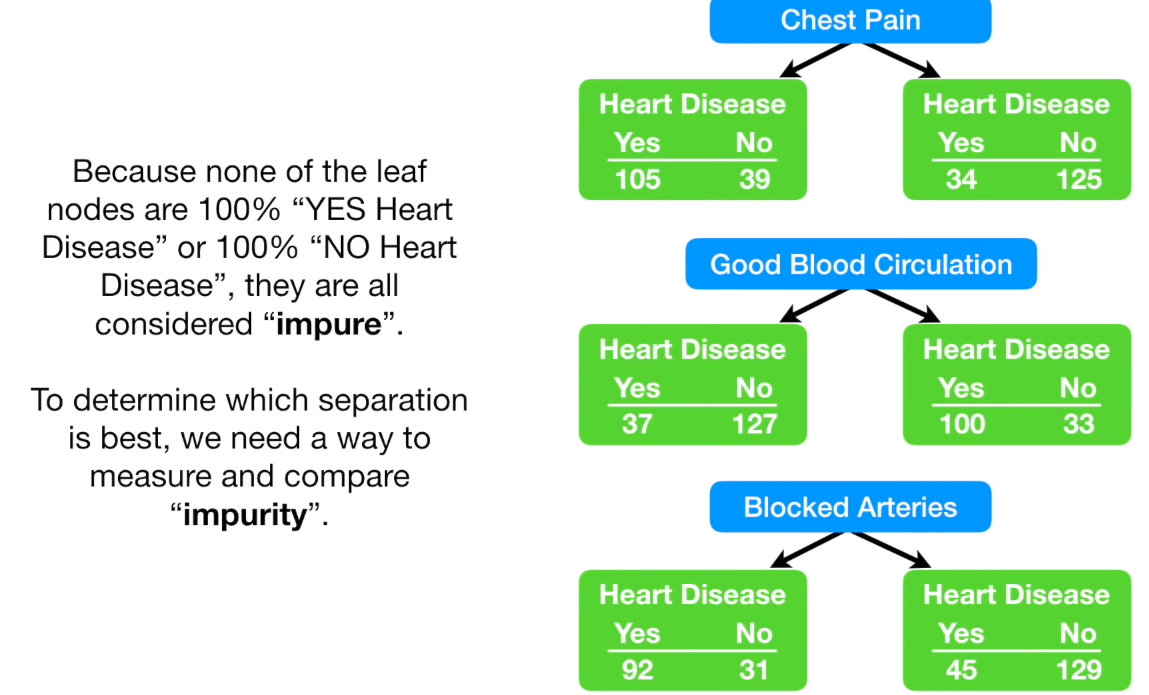
4.1 Metric: Impurity
4.1.1 Entropy
$$im(T)=-\sum_{i=1}^{M}P(\omega_{i}|T)log_{2}P(\omega_{i}|T)$$
$$P(\omega_{i}|T)=\frac{number\: of\: sample\: assigned\: class\: \omega_{i}\: of\: X_{T}}{sample\: size\: of\: X_{T}}$$
Example: when $P(\omega_{1}|T)=\frac{3}{9},(\omega_{2}|T)=\frac{4}{9},(\omega_{3}|T)=\frac{2}{9}$,
$$im(T)=-(\frac{3}{9}log_{2}\frac{3}{9}+\frac{4}{9}log_{2}\frac{4}{9}+\frac{2}{9}log_{2}\frac{2}{9})=1.5305$$
4.1.2 Gini impurity
$$im(T)=1-\sum_{i=1}^{M}P(\omega_{i}|T)^{2}=\sum_{i\neq j}P(\omega_{i}|T)P(\omega_{j}|T)$$
Example: when $P(\omega_{1}|T)=\frac{3}{9},(\omega_{2}|T)=\frac{4}{9},(\omega_{3}|T)=\frac{2}{9}$,
$$im(T)=1-(\frac{3^{2}}{9^{2}}+\frac{4^{2}}{9^{2}}+\frac{2^{2}}{9^{2}})=0.642$$
4.1.3 misclassification impurity
$$im(T)=1-\underset{i}{max}P(\omega_{i}|T)$$
Example: when $P(\omega_{1}|T)=\frac{3}{9},(\omega_{2}|T)=\frac{4}{9},(\omega_{3}|T)=\frac{2}{9}$,
$$im(T)=1-\frac{4}{9}=0.556$$
4.1.4 Metric: Information gain
4.1.5 Metric: variance reduction
4.2 Pick Separation

4.2.1 Metric of picking separation: decrease in impurity $\triangle im(T)$
$$\triangle im(T)=im(T)-\frac{\left | X_{Tleft} \right |}{\left | X_{T} \right |}im(T_{left})-\frac{\left | X_{Tright} \right |}{\left | X_{T} \right |}im(T_{right})$$
Picking separation to maxize $\triangle im(T)$
4.2.2 Metric of picking separation: twoing criteria
$$\triangle im(T)=im(T)-\frac{\left | X_{Tleft} \right |}{\left | X_{T} \right |}\frac{\left | X_{Tright} \right |}{\left | X_{T} \right |}(\sum_{i=1}^{M}\left | p(\omega_{i}|T_{left})-p(\omega_{i}|T_{right}) \right |)^{2}$$
4.3 End condition
4.3.1 Impurity 0
4.3.2 number of samples to separate is lower than theshold
4.3.3 decrease in impurity is lower than theshold
5. Reference
https://www.youtube.com/watch?v=7VeUPuFGJHk
https://en.wikipedia.org/wiki/Decision_tree_learning
https://link.springer.com/content/pdf/10.1007/BF00117831.pdf
https://www.slideshare.net/JeonghunYoon/decision-tree-75370450
'MLAI > Classification' 카테고리의 다른 글
Kernel SVM (0) 2020.01.21 Support Vector Machine (SVM) (0) 2020.01.20 K-Nearest Neighbors (KNN) (0) 2020.01.20 Naive Bayes classifier (0) 2019.10.06 Hidden Markov Model(HMM) (0) 2019.10.04