-
Resilient Distributed Dataset(RDD)DistributedSystem/Spark 2019. 9. 8. 22:32
1. Overview
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
There are two ways to create RDDs − parallelizing an existing collection in your driver program or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations.
2. Description
2.1 Keyword of RDDs
Feature Description Resilient fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures Distributed Data residing on multiple nodes in a cluster Dataset A collection of partitioned data with primitive values or values of values, e.g. tuples or other objects that represent records of the data you work with 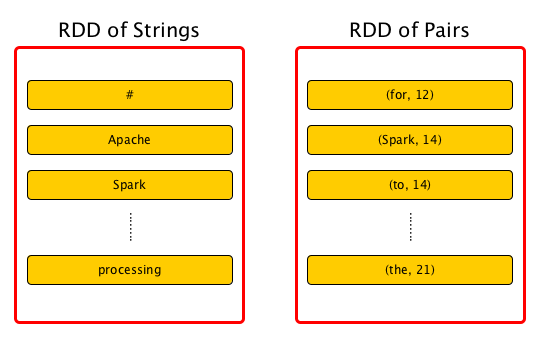
2.2 Traits
Traits Description In-Memory The data inside RDD is stored in memory as much size and long time as possible Immutable(Read-only) Not change once created and can only be transformed using transformations to new RDDs Lazy evaluated The data inside RDD is not available or transformed until an action is executed that triggers the execution Cacheable Being able to hold all the data in persistent storage like memory which default and most preferred or disk the least preferred due to access speed Parallel process data in parallel Typed RDD records have types, e.g. Long in RDD[long] or (Int, String) in RDD[(Int, String)] Partitioned Records are partitioned split into logical partitions and distributed across nodes in a cluster Location-Stickiness RDD can define placement preferences to compute partitions as close to the records as possible 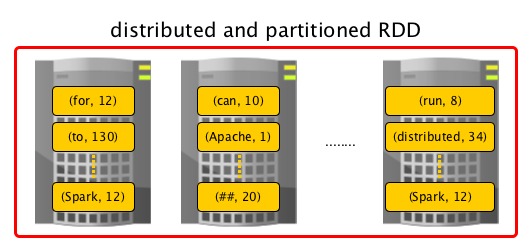
2.3 Terminology
Terminology Description Partitions - The units of parallelism
- Each partition comprised of records
- Being able to control the number of partitions of an RDD using repartition or coalesce transformations.
Transformations Lazy operations that return another RDD Actions Operations that trigger computation and return values Data locality Spark tries to be as close to data as possible without wasting time to send data across a network by means of RDD shuffling RDD shuffling - Process of redistributing data across partitions(aka repartitioning) that may or may not cause moving data across JVM processes or even over the wire
- Leverage partial aggregation to reduce data transfer
Intermediate result Reused intermediate in-memory results across multiple data-intensive workloads with no need for copying large amounts of data over the network 2.4 Contract
Contract Description Parent RDDs RDD dependencies An array of partitions a dataset is divided to A compute function Doing a computation on partitions Optional preferred locations aka locality info. hosts for a partition where the records live or are the closest to read from 2.5 Representing RDDs
Features Description Partition Represent atomic pieces of the dataset Dependencies List of dependencies that an RDD has on its parent RDDs or data sources
- Narrow Dependencies: Where each partition of the parent node is used by at most one child partition. For example, map and filter operations
- Wide Dependencies: Where multiple child partitions user a single parent partition.
Iterator a function that computes an RDD based on its parents partitioner Whether data is range/hash partitioned preferredLocation Nodes where a partition can be accessed faster due to data locality 2.6 Transformation
A lazy operation on an RDD that returns another RDD, like map, flatMap, filter, reduceBy, join, cogroup, etc.
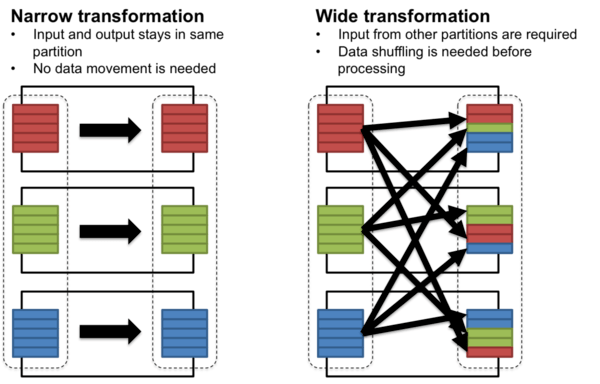
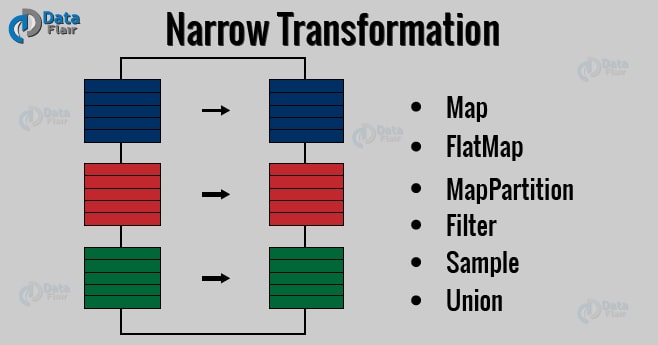

2.7 Types of RDDs
name Description ParallelCollectionRDD - A collection of elements with numSlices partitions and optional location press
- The result of SparkContext.parallelize and SparkContext.makeRDD methods
- The data collection is split on the numSlices slices.
CoGroupedRDD - An RDD that cogroups its pair RDD parents
- For each key k in parent RDDs, the resulting RDD contains a tuple with the list of values for that key
HadoopRDD - An RDD that provides core functionality for reading data stored in HDFS using the older MapReduce API
- The most notable use case is the return RDD of SparkContext.textFile
MapPartitionsRDD - A result of calling operations like map, flatMap, filter, mapPartitions, etc.
CoalescedRDD - A result of repartition or coalesce transformations
- Coalesce Transformation can trigger RDD shuffling depending on the shuffle flag
ShuffledRDD A result of shuffling, e.g. after repartition or coalesce transformations PipedRDD An RDD created by piping elements to a forked external process PairRDD (implicit conversion by PairRDDFunctions) An RDD of key-value pairs that a result of groupByKey and join operations DoubleRDD (implicit conversion as org.apache.spark.rdd.DoubleRDDFunctions) that is an RDD of Double type SequenceFileRDD (implicit conversion as org.apache.spark.rdd.SequenceFileRDDFunctions) that is an RDD that can be saved as a SequenceFile 3. Example
3.1 Creating RDDs
3.1.1 SparkContext.parallelize
- Mainly used to learn Spark in the Spark shell
- Requires all the data to be available on a single machine
scala> val rdd = sc.parallelize(1 to 1000) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25 scala> val data = Seq.fill(10)(util.Random.nextInt) data: Seq[Int] = List(-964985204, 1662791, -1820544313, -383666422, -111039198, 310967683, 1114081267, 1244509086, 1797452433, 124035586) scala> val rdd = sc.parallelize(data) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:293.1.2 SparkContext.textFile
Creating RDD from reading files
scala> val words = sc.textFile("README.md").flatMap(_.split("\\W+")).cache words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[27] at flatMap at <console>:244. References
https://data-flair.training/blogs/spark-rdd-tutorial/
https://www.tutorialspoint.com/apache_spark/apache_spark_rdd.htm
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-rdd.html
'DistributedSystem > Spark' 카테고리의 다른 글
MapReduce Vs Spark RDD (0) 2019.09.25 RDD Lineage and Logical Execution Plan (0) 2019.09.25 Difference between RDD and DSM (0) 2019.09.25 Apache Spark (0) 2019.09.20