-
Metrics: Accuracy, Precision, Sensitivity, Specificity, and F1 scoreStats 2019. 9. 27. 14:03
1. Overview
In pattern recognition, information retrieval and classification, precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances, while recall (aka sensitivity) is the fraction of relevant instances that have been retrieved over the total amount of relevant instances. Both precision and recall are therefore based on an understanding and measure of relevance.
2. Description
2.1 Performance Measures

- TP: True positive

- TN: True Negative

- FP: False positive

- FN: False negative

2.2 Accuracy
Accuracy is calculated as the total number of correct predictions divided by the total number of a dataset.
$$Accuracy = \frac{TP+TN}{TP+TN+FP+FN}$$

2.2.1 Application
- Balanced Data

- Imbalanced Data

Accuracy works well on balanced data, but not on imbalanced data.
2.3 Precision
Precision is the ratio of correctly predicted positive observations to the total predicted positive observations.
$$Precision = \frac{TP}{TP+FP}$$

2.4 Recall or Sensitivity
Recall is the ratio of correctly predicted positive observations to all observations in an actual class
$$Precision = \frac{TP}{TP+FN}$$

2.5 specificity
$$Specificity = \frac{TN}{TN+FP}$$
2.7 F1 score
A measure that combines precision and recall is the harmonic mean of precision and recall, the traditional F-measure or balanced F-score
$$F1 = \frac{Precision\cdot Recall}{Precision+Recall}$$

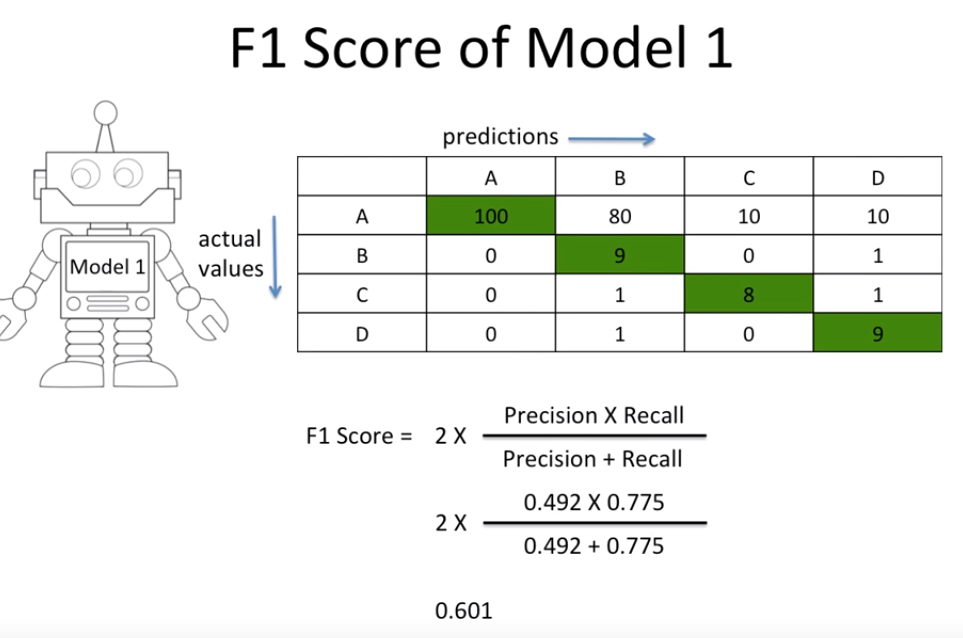
2.7.1 Application on Imbalanced data



3. The advantage of sensitivity and specificity
valuating a model based on both, sensitivity and specificity, is appropriate for most data sets because these measures consider all entries in the confusion matrix. While sensitivity deals with true positives and false negatives, specificity deals with false positives and true negatives. This means that the combination of sensitivity and specificity is a holistic measure when both true positives and true negatives should be considered.
Sensitivity and specificity can be summarized by a single quantity, the balanced accuracy, which is defined as the mean of both measures:
$$balanced accuracy=\frac{sensitivity+specificity}{2}$$
The balanced accuracy is in the range [0,1] where values of 0 and 1 indicate the worst-possible and the best-possible classifier, respectively.
4. The disadvantage of recall and precision
Evaluating a model using recall and precision does not use all cells of the confusion matrix. Recall deals with true positives and false negatives and precision deals with true positives and false positives. Thus, using this pair of performance measures, true negatives are never taken into account. Thus, precision and recall should only be used in situations, where the correct identification of the negative class does not play a role. This is why these measures originate from information retrieval where precision can be defined as
$$precision=\frac{\left | \left \{ relevant\: documents \right \} \cap \left \{ retrieved\: documents \right \} \right |}{\left | \left \{ retrieved\: documents \right \} \right |}$$
Here, it does not matter at which rate irrelevant documents are correctly discarded (true negative rate) because it is of no consequence.
Precision and recall are often summarized as a single quantity, the F1-score, which is the harmonic mean of both measures:
$$F1=2\times \frac{recall\times precision}{recall+precision}$$
F1 is in the range [0,1][0,1] and will be 1 for a classifier maximizing precision and recall. Since it is based on the harmonic mean, the F1-score is very sensitive towards disparate values for precision and recall. Assume a classifier has a sensitivity of 90% and a precision of 30%. Then the conventional mean would be $\frac{0.9+0.3}{2}=0.6$ but the harmonic mean (F1 score) would be $2\times \frac{0.9\times 0.3}{0.9+0.3}=0.45$.
5. References
https://www.youtube.com/watch?v=HBi-P5j0Kec
https://en.wikipedia.org/wiki/F1_score
https://en.wikipedia.org/wiki/Precision_and_recall
https://towardsdatascience.com/accuracy-precision-recall-or-f1-331fb37c5cb9
https://www.datascienceblog.net/post/machine-learning/specificity-vs-precision/
'Stats' 카테고리의 다른 글
Accept-Reject Sampling (1) 2022.07.14 Terminology (0) 2020.01.15 Population, Sample, and Sampling (0) 2020.01.11 Relationship between MLE and MAP (0) 2019.10.04 p-value (0) 2019.09.27